(PresseBox) (GENF, Schweiz, 15.05.2012) Die unabhängige Privatbank Bankhaus Main nutzt ab sofort die Lösung Triple’A Plus des Bankensoftwarespezialisten Temenos als neue Portfoliomanagement-Plattform. Das System für das gesamte Unternehmen wurde in …
temenos – Bing News
An important and controversial topic in the area of personal wallet security is the concept of “brainwallets” – storing funds using a private key generated from a password memorized entirely in one’s head. Theoretically, brainwallets have the potential to provide almost utopian guarantee of security for long-term savings: for as long as they are kept unused, they are not vulnerable to physical theft or hacks of any kind, and there is no way to even prove that you still remember the wallet; they are as safe as your very own human mind. At the same time, however, many have argued against the use of brainwallets, claiming that the human mind is fragile and not well designed for producing, or remembering, long and fragile cryptographic secrets, and so they are too dangerous to work in reality. Which side is right? Is our memory sufficiently robust to protect our private keys, is it too weak, or is perhaps a third and more interesting possibility actually the case: that it all depends on how the brainwallets are produced?
Entropy
If the challenge at hand is to create a brainwallet that is simultaneously memorable and secure, then there are two variables that we need to worry about: how much information we have to remember, and how long the password takes for an attacker to crack. As it turns out, the challenge in the problem lies in the fact that the two variables are very highly correlated; in fact, absent a few certain specific kinds of special tricks and assuming an attacker running an optimal algorithm, they are precisely equivalent (or rather, one is precisely exponential in the other). However, to start off we can tackle the two sides of the problem separately.
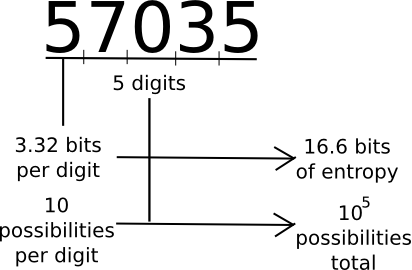
A common measure that computer scientists, cryptogaphers and mathematicians use to measure “how much information” a piece of data contains is “entropy”. Loosely defined, entropy is defined as the logarithm of the number of possible messages that are of the same “form” as a given message. For example, consider the number 57035. 57035 seems to be in the category of five-digit numbers, of which there are 100000. Hence, the number contains about 16.6 bits of entropy, as 216.6 ~= 100000. The number 61724671282457125412459172541251277 is 35 digits long, and log(1035) ~= 116.3, so it has 116.3 bits of entropy. A random string of ones and zeroes n bits long will contain exactly n bits of entropy. Thus, longer strings have more entropy, and strings that have more symbols to choose from have more entropy.
On the other hand, the number 11111111111111111111111111234567890 has much less than 116.3 bits of entropy; although it has 35 digits, the number is not of the category of 35-digit numbers, it is in the category of 35-digit numbers with a very high level of structure; a complete list of numbers with at least that level of structure might be at most a few billion entries long, giving it perhaps only 30 bits of entropy.
Information theory has a number of more formal definitions that try to grasp this intuitive concept. A particularly popular one is the idea of Kolmogorov complexity; the Kolmogorov complexity of a string is basically the length of the shortest computer program that will print that value. In Python, the above string is also expressible as '1'*26+'234567890' – an 18-character string, while 61724671282457125412459172541251277 takes 37 characters (the actual digits plus quotes). This gives us a more formal understanding of the idea of “category of strings with high structure” – those strings are simply the set of strings that take a small amount of data to express. Note that there are other compression strategies we can use; for example, unbalanced strings like 1112111111112211111111111111111112111 can be cut by at least half by creating special symbols that represent multiple 1s in sequence. Huffman coding is an example of an information-theoretically optimal algorithm for creating such transformations.
Finally, note that entropy is context-dependent. The string “the quick brown fox jumped over the lazy dog” may have over 100 bytes of entropy as a simple Huffman-coded sequence of characters, but because we know English, and because so many thousands of information theory articles and papers have already used that exact phrase, the actual entropy is perhaps around 25 bytes – I might refer to it as “fox dog phrase” and using Google you can figure out what it is.
So what is the point of entropy? Essentially, entropy is how much information you have to memorize. The more entropy it has, the harder to memorize it is. Thus, at first glance it seems that you want passwords that are as low-entropy as possible, while at the same time being hard to crack. However, as we will see below this way of thinking is rather dangerous.
Strength
Now, let us get to the next point, password security against attackers. The security of a password is best measured by the expected number of computational steps that it would take for an attacker to guess your password. For randomly generated passwords, the simplest algorithm to use is brute force: try all possible one-character passwords, then all two-character passwords, and so forth. Given an alphabet of n characters and a password of length k, such an algorithm would crack the password in roughly nk time. Hence, the more characters you use, the better, and the longer your password is, the better.
There is one approach that tries to elegantly combine these two strategies without being too hard to memorize: Steve Gibson’s haystack passwords. As Steve Gibson explains:
Which of the following two passwords is stronger, more secure, and more difficult to crack?
D0g………………… PrXyc.N(n4k77#L!eVdAfp9 You probably know this is a trick question, but the answer is: Despite the fact that the first password is HUGELY easier to use and more memorable, it is also the stronger of the two! In fact, since it is one character longer and contains uppercase, lowercase, a number and special characters, that first password would take an attacker approximately 95 times longer to find by searching than the second impossible-to-remember-or-type password!
Steve then goes on to write: “Virtually everyone has always believed or been told that passwords derived their strength from having “high entropy”. But as we see now, when the only available attack is guessing, that long-standing common wisdom . . . is . . . not . . . correct!” However, as seductive as such a loophole is, unfortunately in this regard he is dead wrong. The reason is that it relies on specific properties of attacks that are commonly in use, and if it becomes widely used attacks could easily emerge that are specialized against it. In fact, there is a generalized attack that, given enough leaked password samples, can automatically update itself to handle almost anything: Markov chain samplers.
The way the algorithm works is as follows. Suppose that the alphabet that you have consists only of the characters 0 and 1, and you know from sampling that a 0 is followed by a 1 65% of the time and a 0 35% of the time, and a 1 is followed by a 0 20% of the time and a 1 80% of the time. To randomly sample the set, we create a finite state machine containing these probabilities, and simply run it over and over again in a loop.
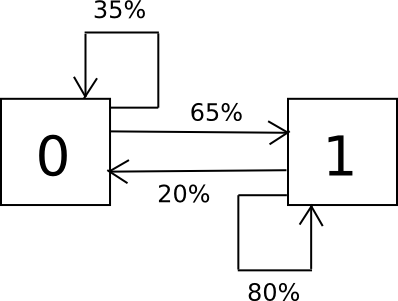
Here’s the Python code:
import random i = 0 while 1: if i == 0: i = 0 if random.randrange(100) < 35 else 1 elif i == 1: i = 0 if random.randrange(100) < 20 else 1 print i We take the output, break it up into pieces, and there we have a way of generating passwords that have the same pattern as passwords that people actually use. We can generalize this past two characters to a complete alphabet, and we can even have the state keep track not just of the last character but the last two, or three or more. So if everyone starts making passwords like “D0g…………………”, then after seeing a few thousand examples the Markov chain will “learn” that people often make long strings of periods, and if it spits out a period it will often get itself temporarily stuck in a loop of printing out more periods for a few steps – probabilistically replicating people’s behavior.
The one part that was left out is how to terminate the loop; as given, the code simply gives an infinite string of zeroes and ones. We could introduce a pseudo-symbol into our alphabet to represent the end of a string, and incorporate the observed rate of occurrences of that symbol into our Markov chain probabilities, but that’s not optimal for this use case – because far more passwords are short than long, it would usually output passwords that are very short, and so it would repeat the short passwords millions of times before trying most of the long ones. Thus we might want to artificially cut it off at some length, and increase that length over time, although more advanced strategies also exist like running a simultaneous Markov chain backwards. This general category of method is usually called a “language model” – a probability distribution over sequences of characters or words which can be as simple and rough or as complex and intricate as needed, and which can then be sampled.
The fundamental reason why the Gibson strategy fails, and why no other strategy of that kind can possibly work, is that in the definitions of entropy and strength there is an interesting equivalence: entropy is the logarithm of the number of possibilities, but strength is the number of possibilities – in short, memorizability and attackability are invariably exactly the same! This applies regardless of whether you are randomly selecting characters from an alphabet, words from a dictionary, characters from a biased alphabet (eg. “1″ 80% of the time and “0″ 20% of the time, or strings that follow a particular pattern). Thus, it seems that the quest for a secure and memorizable password is hopeless…
Easing Memory, Hardening Attacks
… or not. Although the basic idea that entropy that needs to be memorized and the space that an attacker needs to burn through are exactly the same is mathematically and computationally correct, the problem lives in the real world, and in the real world there are a number of complexities that we can exploit to shift the equation to our advantage.
The first important point is that human memory is not a computer-like store of data; the extent to which you can accurately remember information often depends on how you memorize it, and in what format you store it. For example, we implicitly memorize kilobytes of information fairly easily in the form of human faces, but even something as similar in the grand scheme of things as dog faces are much harder for us. Information in the form of text is even harder – although if we memorize the text visually and orally at the same time it’s somewhat easier again.
Some have tried to take advantage of this fact by generating random brainwallets and encoding them in a sequence of words; for example, one might see something like:
witch collapse practice feed shame open despair creek road again ice least A popular XKCD comic illustrates the principle, suggesting that users create passwords by generating four random words instead of trying to be clever with symbol manipulation. The approach seems elegant, and perhaps taking away of our differing ability to remember random symbols and language in this way, it just might work. Except, there’s a problem: it doesn’t.
To quote a recent study by Richard Shay and others from Carnegie Mellon:
In a 1,476-participant online study, we explored the usability of 3- and 4-word system- assigned passphrases in comparison to system-assigned passwords composed of 5 to 6 random characters, and 8-character system-assigned pronounceable passwords. Contrary to expectations, sys- tem-assigned passphrases performed similarly to system-assigned passwords of similar entropy across the usability metrics we ex- amined. Passphrases and passwords were forgotten at similar rates, led to similar levels of user difficulty and annoyance, and were both written down by a majority of participants. However, passphrases took significantly longer for participants to enter, and appear to require error-correction to counteract entry mistakes. Passphrase usability did not seem to increase when we shrunk the dictionary from which words were chosen, reduced the number of words in a passphrase, or allowed users to change the order of words.
However, the paper does leave off on a note of hope. It does note that there are ways to make passwords that are higher entropy, and thus higher security, while still being just as easy to memorize; randomly generated but pronounceable strings like “zelactudet” (presumably created via some kind of per-character language model sampling) seem to provide a moderate gain over both word lists and randomly generated character strings. A likely cause of this is that pronounceable passwords are likely to be memorized both as a sound and as a sequence of letters, increasing redundancy. Thus, we have at least one strategy for improving memorizability without sacrificing strength.
The other strategy is to attack the problem from the opposite end: make it harder to crack the password without increasing entropy. We cannot make the password harder to crack by adding more combinations, as that would increase entropy, but what we can do is use what is known as a hard key derivation function. For example, suppose that if our memorized brainwallet is b, instead of making the private key sha256(b) or sha3(b), we make it F(b, 1000) where F is defined as follows:
def F(b, rounds): x = b i = 0 while i < rounds: x = sha3(x + b) i += 1 return x Essentially, we keep feeding b into the hash function over and over again, and only after 1000 rounds do we take the output.

Feeding the original input back into each round is not strictly necessary, but cryptographers recommend it in order to limit the effect of attacks involving precomputed rainbow tables. Now, checking each individual password takes a thousand time longer. You, as the legitimate user, won’t notice the difference – it’s 20 milliseconds instead of 20 microseconds – but against attackers you get ten bits of entropy for free, without having to memorize anything more. If you go up to 30000 rounds you get fifteen bits of entropy, but then calculating the password takes close to a second; 20 bits takes 20 seconds, and beyond about 23 it becomes too long to be practical.
Now, there is one clever way we can go even further: outsourceable ultra-expensive KDFs. The idea is to come up with a function which is extremely expensive to compute (eg. 240 computational steps), but which can be computed in some way without giving the entity computing the function access to the output. The cleanest, but most cryptographically complicated, way of doing this is to have a function which can somehow be “blinded” so unblind(F(blind(x))) = F(x) and blinding and unblinding requires a one-time randomly generated secret. You then calculate blind(password), and ship the work off to a third party, ideally with an ASIC, and then unblind the response when you receive it.
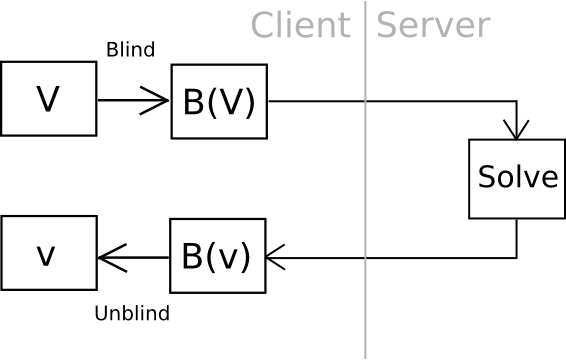
One example of this is using elliptic curve cryptography: generate a weak curve where the values are only 80 bits long instead of 256, and make the hard problem a discrete logarithm computation. That is, we calculate a value x by taking the hash of a value, find the associated y on the curve, then we “blind” the (x,y) point by adding another randomly generated point, N (whose associated private key we know to be n), and then ship the result off to a server to crack. Once the server comes up with the private key corresponding to N + (x,y), we subtract n, and we get the private key corresponding to (x,y) – our intended result. The server does not learn any information about what this value, or even (x,y), is – theoretically it could be anything with the right blinding factor N. Also, note that the user can instantly verify the work – simply convert the private key you get back into a point, and make sure that the point is actually (x,y).
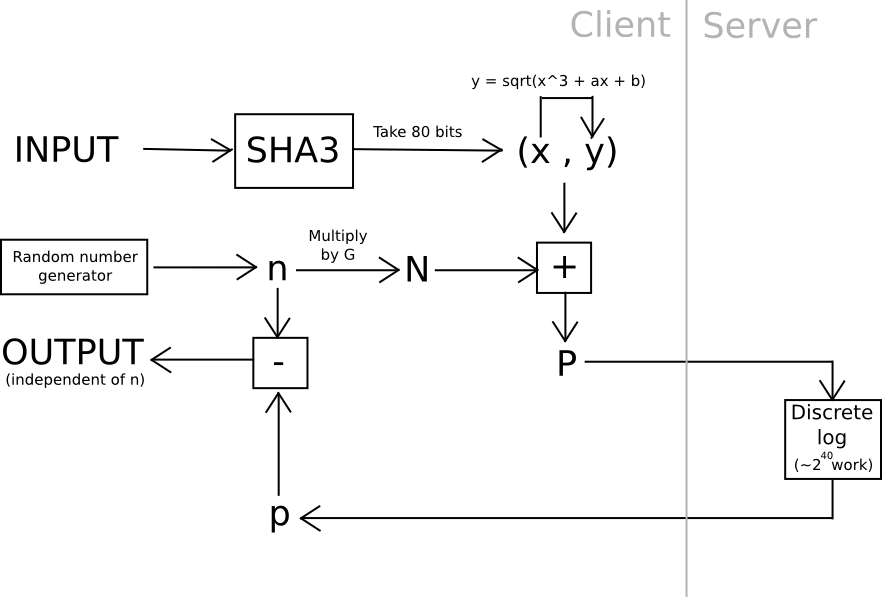
Another approach relies somewhat less on algebraic features of nonstandard and deliberately weak elliptic curves: use hashes to derive 20 seeds from a password, apply a very hard proof of work problem to each one (eg. calculate f(h) = n where n is such that sha3(n+h) < 2^216), and combine the values using a moderately hard KDF at the end. Unless all 20 servers collude (which can be avoided if the user connects through Tor, since it would be impossible even for an attacker controlling or seeing the results of 100% of the network to determine which requests are coming from the same user), the protocol is secure.
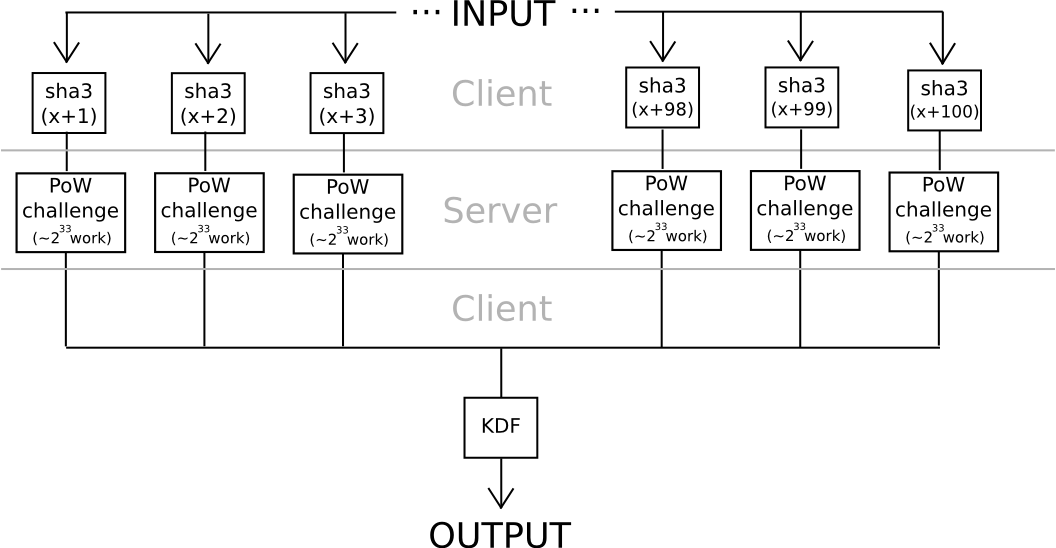
The interesting thing about both of these protocols is that they are fairly easy to turn into a “useful proof of work” consensus algorithm for a blockchain; anyone could submit work for the chain to process, the chain would perform the computations, and both elliptic curve discrete logs and hash-based proofs of work are very easy to verify. The elegant part of the scheme is that it turns to social use both users’ expenses in computing the work function, but also attackers’ much greater expenses. If the blockchain subsidized the proof of work, then it would be optimal for attackers to also try to crack users’ passwords by submitting work to the blockchain, in which case the attackers would contribute to the consensus security in the process. But then, in reality at this level of security, where 240 work is needed to compute a single password, brainwallets and other passwords would be so secure that no one would even bother attacking them.
Entropy Differentials
Now, we get to our final, and most interesting, memorization strategy. From what we discussed above, we know that entropy, the amount of information in a message, and the complexity of attack are exactly identical – unless you make the process deliberately slower with expensive KDFs. However, there is another point about entropy that was mentioned in passing, and which is actually crucial: experienced entropy is context-dependent. The name “Mahmoud Ahmadjinejad” might have perhaps ten to fifteen bits of entropy to us, but to someone living in Iran while he was president it might have only four bits – in the list of the most important people in their lives, he is quite likely in the top sixteen. Your parents or spouse are completely unknown to myself, and so for me their names have perhaps twenty bits of entropy, but to you they have only two or three bits.
Why does this happen? Formally, the best way to think about it is that for each person the prior experiences of their lives create a kind of compression algorithm, and under different compression algorithms, or different programming languages, the same string can have a different Kolmogorov complexity. In Python, ’111111111111111111′ is just '1'*18, but in Javascript it’s Array(19).join("1"). In a hypothetical version of Python with the variable x preset to ’111111111111111111′, it’s just x. The last example, although seemingly contrived, is actually the one that best describes much of the real world; the human mind is a machine with many variables preset by our past experiences.
This rather simple insight leads to a particularly elegant strategy for password memorizability: try to create a password where the “entropy differential”, the difference between the entropy to you and the entropy to other people, is as large as possible. One simple strategy is to prepend your own username to the password. If my password were to be “yui&(4_”, I might do “vbuterin:yui&(4_” instead. My username might have about ten to fifteen bits of entropy to the rest of the world, but to me it’s almost a single bit. This is essentially the primary reason why usernames exist as an account protection mechanism alongside passwords even in cases where the concept of users having “names” is not strictly necessary.
Now, we can go a bit further. One common piece of advice that is now commonly and universally derided as worthless is to pick a password by taking a phrase out of a book or song. The reason why this idea is seductive is because it seems to cleverly exploit differentials: the phrase might have over 100 bits of entropy, but you only need to remember the book and the page and line number. The problem is, of course, that everyone else has access to the books as well, and they can simply do a brute force attack over all books, songs and movies using that information.
However, the advice is not worthless; in fact, if used as only part of your password, a quote from a book, song or movie is an excellent ingredient. Why? Simple: it creates a differential. Your favorite line from your favorite song only has a few bits of entropy to you, but it’s not everyone’s favorite song, so to the entire world it might have ten or twenty bits of entropy. The optimal strategy is thus to pick a book or song that you really like, but which is also maximally obscure – push your entropy down, and others’ entropy higher. And then, of course, prepend your username and append some random characters (perhaps even a random pronounceable “word” like “zelactudet”), and use a secure KDF.
Conclusion
How much entropy do you need to be secure? Right now, password cracking chips can perform about 236 attempts per second, and Bitcoin miners can perform roughly 240 hashes per second (that’s 1 terahash). The entire Bitcoin network together does 250 petahashes, or about 257 hashes per second. Cryptographers generally consider 280 to be an acceptable minimum level of security. To get 80 bits of entropy, you need either about 17 random letters of the alphabet, or 12 random letters, numbers and symbols. However, we can shave quite a bit off the requirement: fifteen bits for a username, fifteen bits for a good KDF, perhaps ten bits for an abbreviation from a passage from a semi-obscure song or book that you like, and then 40 more bits of plan old simple randomness. If you’re not using a good KDF, then feel free to use other ingredients.
It has become rather popular among security experts to dismiss passwords as being fundamentally insecure, and argue for password schemes to be replaced outright. A common argument is that because of Moore’s law attackers’ power increases by one bit of entropy every two years, so you will have to keep on memorizing more and more to remain secure. However, this is not quite correct. If you use a hard KDF, Moore’s law allows you to take away bits from the attacker’s power just as quickly as the attacker gains power, and the fact that schemes such as those described above, with the exception of KDFs (the moderate kind, not the outsourceable kind), have not even been tried suggests that there is still some way to go. On the whole, passwords thus remain as secure as they have ever been, and remain very useful as one ingredient of a strong security policy – just not the only ingredient. Moderate approaches that use a combination of hardware wallets, trusted third parties and brainwallets may even be what wins out in the end.
The post An Information-Theoretic Account of Secure Brainwallets appeared first on ethereum blog.
Special thanks to Vlad Zamfir, Chris Barnett and Dominic Williams for ideas and inspiration
In a recent blog post I outlined some partial solutions to scalability, all of which fit into the umbrella of Ethereum 1.0 as it stands. Specialized micropayment protocols such as channels and probabilistic payment systems could be used to make small payments, using the blockchain either only for eventual settlement, or only probabilistically. For some computation-heavy applications, computation can be done by one party by default, but in a way that can be “pulled down” to be audited by the entire chain if someone suspects malfeasance. However, these approaches are all necessarily application-specific, and far from ideal. In this post, I describe a more comprehensive approach, which, while coming at the cost of some “fragility” concerns, does provide a solution which is much closer to being universal.
Understanding the Objective
First of all, before we get into the details, we need to get a much deeper understanding of what we actually want. What do we mean by scalability, particularly in an Ethereum context? In the context of a Bitcoin-like currency, the answer is relatively simple; we want to be able to:
- Process tens of thousands of transactions per second
- Provide a transaction fee of less than $ 0.001
- Do it all while maintaining security against at least 25% attacks and without highly centralized full nodes
The first goal alone is easy; we just remove the block size limit and let the blockchain naturally grow until it becomes that large, and the economy takes care of itself to force smaller full nodes to continue to drop out until the only three full nodes left are run by GHash.io, Coinbase and Circle. At that point, some balance will emerge between fees and size, as excessize size leads to more centralization which leads to more fees due to monopoly pricing. In order to achieve the second, we can simply have many altcoins. To achieve all three combined, however, we need to break through a fundamental barrier posed by Bitcoin and all other existing cryptocurrencies, and create a system that works without the existence of any “full nodes” that need to process every transaction.
In an Ethereum context, the definition of scalability gets a little more complicated. Ethereum is, fundamentally, a platform for “dapps”, and within that mandate there are two kinds of scalability that are relevant:
- Allow lots and lots of people to build dapps, and keep the transaction fees low
- Allow each individual dapp to be scalable according to a definition similar to that for Bitcoin
The first is inherently easier than the second. The only property that the “build lots and lots of alt-Etherea” approach does not have is that each individual alt-Ethereum has relatively weak security; at a size of 1000 alt-Etherea, each one would be vulnerable to a 0.1% attack from the point of view of the whole system (that 0.1% is for externally-sourced attacks; internally-sourced attacks, the equivalent of GHash.io and Discus Fish colluding, would take only 0.05%). If we can find some way for all alt-Etherea to share consensus strength, eg. some version of merged mining that makes each chain receive the strength of the entire pack without requiring the existence of miners that know about all chains simultaneously, then we would be done.
The second is more problematic, because it leads to the same fragility property that arises from scaling Bitcoin the currency: if every node sees only a small part of the state, and arbitrary amounts of BTC can legitimately appear in any part of the state originating from any part of the state (such fungibility is part of the definition of a currency), then one can intuitively see how forgery attacks might spread through the blockchain undetected until it is too late to revert everything without substantial system-wide disruption via a global revert.
Reinventing the Wheel
We’ll start off by describing a relatively simple model that does provide both kinds of scalability, but provides the second only in a very weak and costly way; essentially, we have just enough intra-dapp scalability to ensure asset fungibility, but not much more. The model works as follows:
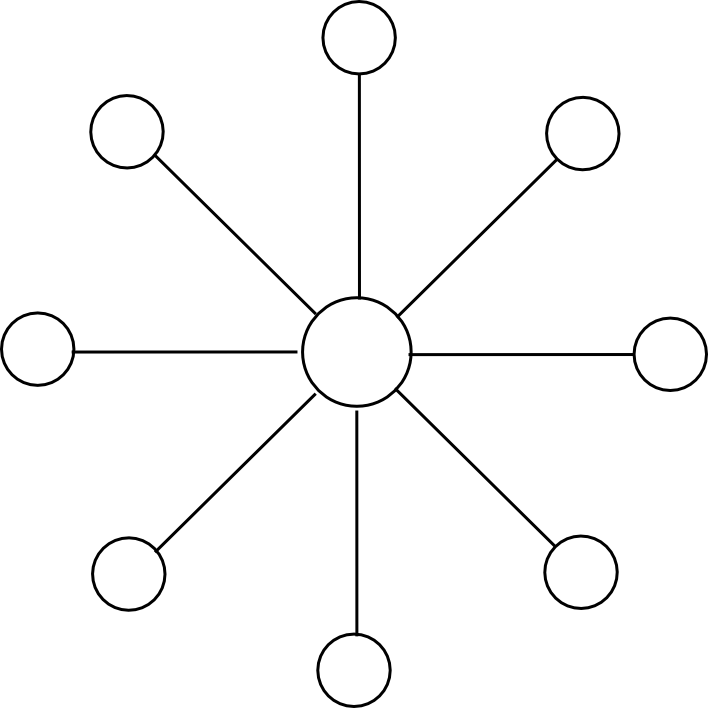
Suppose that the global Ethereum state (ie. all accounts, contracts and balances) is split up into N parts (“substates”) (think 10 <= N <= 200). Anyone can set up an account on any substate, and one can send a transaction to any substate by adding a substate number flag to it, but ordinary transactions can only send a message to an account in the same substate as the sender. However, to ensure security and cross-transmissibility, we add some more features. First, there is also a special “hub substate”, which contains only a list of messages, of the form [dest_substate, address, value, data]. Second, there is an opcode CROSS_SEND, which takes those four parameters as arguments, and sends such a one-way message enroute to the destination substate.
Miners mine blocks on some substate s[j], and each block on s[j] is simultaneously a block in the hub chain. Each block on s[j] has as dependencies the previous block on s[j] and the previous block on the hub chain. For example, with N = 2, the chain would look something like this:
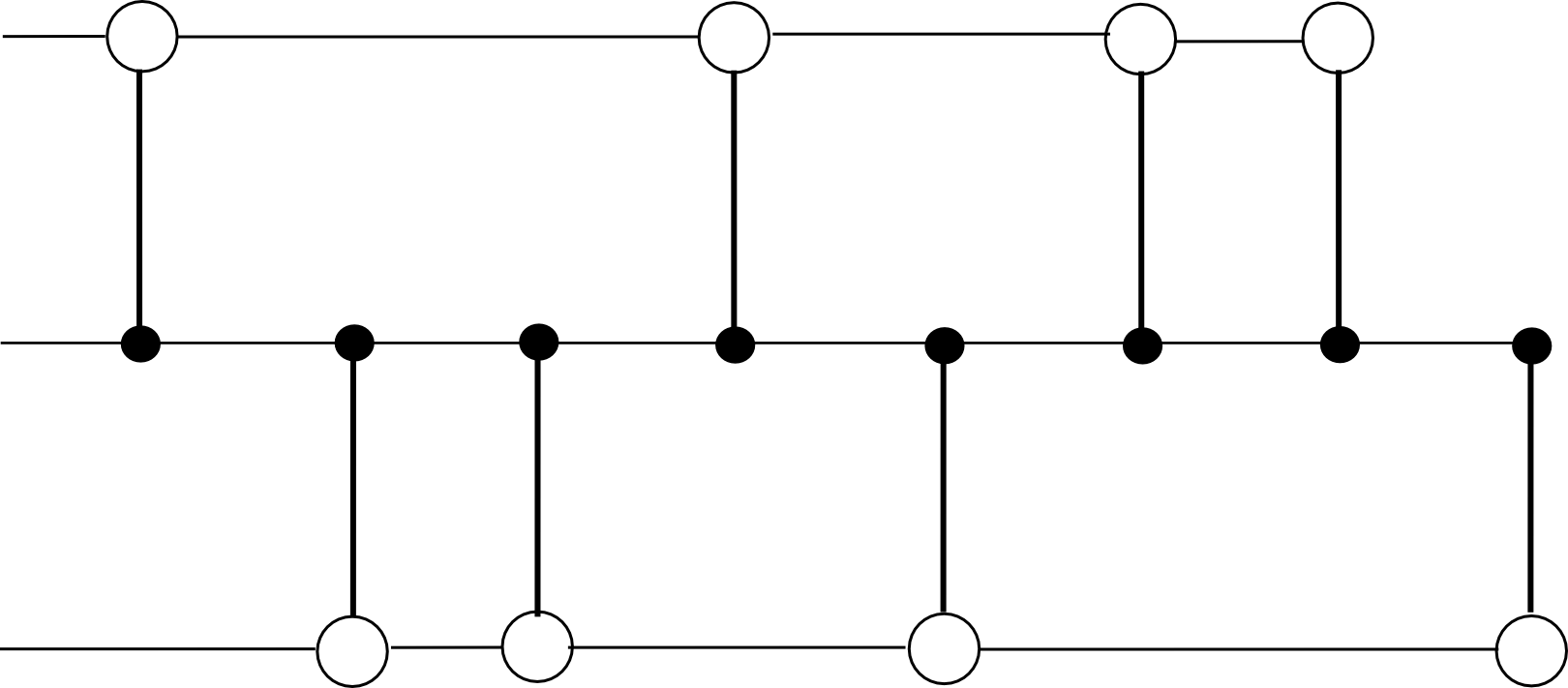
The block-level state transition function does three things:
- Processes state transitions inside of
s[j] - If any of those state transitions creates a
CROSS_SEND, adds that message to the hub chain - If any messages are on the hub chain with
dest_substate = j, removes the messages from the hub chain, sends the messages to their destination addresses ons[j], and processes all resulting state transitions
From a scalability perspective, this gives us a substantial improvement. All miners only need to be aware of two out of the total N + 1 substates: their own substate, and the hub substate. Dapps that are small and self-contained will exist on one substate, and dapps that want to exist across multiple substates will need to send messages through the hub. For example a cross-substate currency dapp would maintain a contract on all substates, and each contract would have an API that allows a user to destroy currency units inside of one substate in exchange for the contract sending a message that would lead to the user being credited the same amount on another substate.
Messages going through the hub do need to be seen by every node, so these will be expensive; however, in the case of ether or sub-currencies we only need the transfer mechanism to be used occasionally for settlement, doing off-chain inter-substate exchange for most transfers.
Attacks, Challenges and Responses
Now, let us take this simple scheme and analyze its security properties (for illustrative purposes, we’ll use N = 100). First of all, the scheme is secure against double-spend attacks up to 50% of the total hashpower; the reason is that every sub-chain is essentially merge-mined with every other sub-chain, with each block reinforcing the security of all sub-chains simultaneously.
However, there are more dangerous classes of attacks as well. Suppose that a hostile attacker with 4% hashpower jumps onto one of the substates, thereby now comprising 80% of the mining power on it. Now, that attacker mines blocks that are invalid – for example, the attacker includes a state transition that creates messages sending 1000000 ETH to every other substate out of nowhere. Other miners on the same substate will recognize the hostile miner’s blocks as invalid, but this is irrelevant; they are only a very small part of the total network, and only 20% of that substate. The miners on other substates don’t know that the attacker’s blocks are invalid, because they have no knowledge of the state of the “captured substate”, so at first glance it seems as though they might blindly accept them.
Fortunately, here the solution here is more complex, but still well within the reach of what we currently know works: as soon as one of the few legitimate miners on the captured substate processes the invalid block, they will see that it’s invalid, and therefore that it’s invalid in some particular place. From there, they will be able to create a light-client Merkle tree proof showing that that particular part of the state transition was invalid. To explain how this works in some detail, a light client proof consists of three things:
- The intermediate state root that the state transition started from
- The intermediate state root that the state transition ended at
- The subset of Patricia tree nodes that are accessed or modified in the process of executing the state transition
The first two “intermediate state roots” are the roots of the Ethereum Patricia state tree before and after executing the transaction; the Ethereum protocol requires both of these to be in every block. The Patricia state tree nodes provided are needed in order to the verifier to follow along the computation themselves, and see that the same result is arrived at the end. For example, if a transaction ends up modifying the state of three accounts, the set of tree nodes that will need to be provided might look something like this:
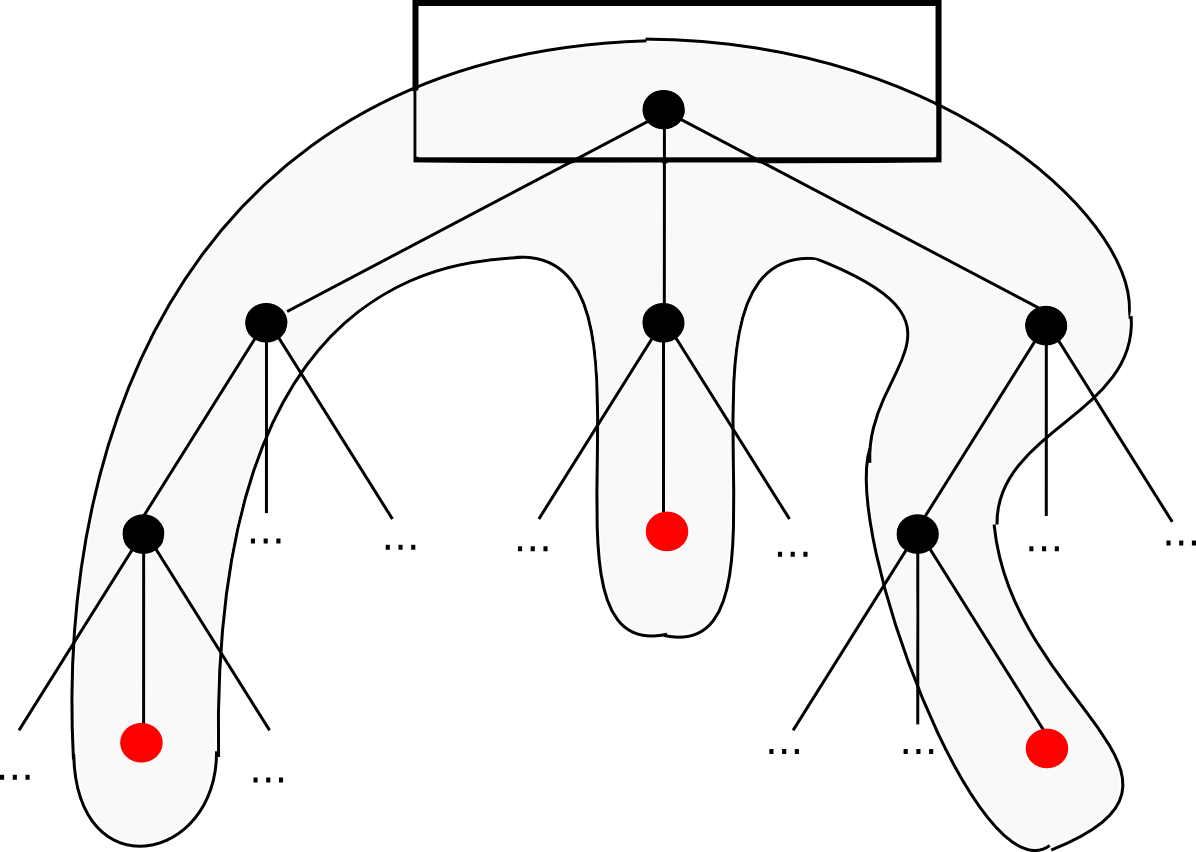
Technically, the proof should include the set of Patricia tree nodes that are needed to access the intermediate state roots and the transaction as well, but that’s a relatively minor detail. Altogether, one can think of the proof as consisting of the minimal amount of information from the blockchain needed to process that particular transaction, plus some extra nodes to prove that those bits of the blockchain are actually in the current state. Once the whistleblower creates this proof, they will then be broadcasted to the network, and all other miners will see the proof and discard the defective block.
The hardest class of attack of all, however, is what is called a “data unavailability attack”. Here, imagine that the miner sends out only the block header to the network, as well as the list of messages to add to the hub, but does not provide any of the transactions, intermediate state roots or anything else. Now, we have a problem. Theoretically, it is entirely possible that the block is completely legitimate; the block could have been properly constructed by gathering some transactions from a few millionaires who happened to be really generous. In reality, of course, this is not the case, and the block is a fraud, but the fact that the data is not available at all makes it impossible to construct an affirmative proof of the fraud. The 20% honest miners on the captured substate may yell and squeal, but they have no proof at all, and any protocol that did heed their words would necessarily fall to a 0.2% denial-of-service attack where the miner captures 20% of a substate and pretends that the other 80% of miners on that substate are conspiring against him.
To solve this problem, we need something called a challenge-response protocol. Essentially, the mechanism works as follows:
- Honest miners on the captured substate see the header-only block.
- An honest miner sends out a “challenge” in the form of an index (ie. a number).
- If the producer of the block can submit a “response” to the challenge, consisting of a light-client proof that the transaction execution at the given index was executed legitimately (or a proof that the given index is greater than the number of transactions in the block), then the challenge is deemed answered.
- If a challenge goes unanswered for a few seconds, miners on other substates consider the block suspicious and refuse to mine on it (the game-theoretic justification for why is the same as always: because they suspect that others will use the same strategy, and there is no point mining on a substate that will soon be orphaned)
Note that the mechanism requires a few added complexities on order to work. If a block is published alongside all of its transactions except for a few, then the challenge-response protocol could quickly go through them all and discard the block. However, if a block was published truly headers-only, then if the block contained hundreds of transactions, hundreds of challenges would be required. One heuristic approach to solving the problem is that miners receiving a block should privately pick some random nonces, send out a few challenges for those nonces to some known miners on the potentially captured substate, and if responses to all challenges do not come back immediately treat the block as suspect. Note that the miner does NOT broadcast the challenge publicly – that would give an opportunity for an attacker to quickly fill in the missing data.
The second problem is that the protocol is vulnerable to a denial-of-service attack consisting of attackers publishing very very many challenges to legitimate blocks. To solve this, making a challenge should have some cost – however, if this cost is too high then the act of making a challenge will require a very high “altruism delta”, perhaps so high that an attack will eventually come and no one will challenge it. Although some may be inclined to solve this with a market-based approach that places responsibility for making the challenge on whatever parties end up robbed by the invalid state transition, it is worth noting that it’s possible to come up with a state transition that generates new funds out of nowhere, stealing from everyone very slightly via inflation, and also compensates wealthy coin holders, creating a theft where there is no concentrated incentive to challenge it.
For a currency, one “easy solution” is capping the value of a transaction, making the entire problem have only very limited consequence. For a Turing-complete protocol the solution is more complex; the best approaches likely involve both making challenges expensive and adding a mining reward to them. There will be a specialized group of “challenge miners”, and the theory is that they will be indifferent as to which challenges to make, so even the tiniest altruism delta, enforced by software defaults, will drive them to make correct challenges. One may even try to measure how long challenges take to get responded, and more highly reward the ones that take longer.
The Twelve-Dimensional Hypercube
Note: this is NOT the same as the erasure-coding Borg cube. For more info on that, see here: https://blog.ethereum.org/2014/08/16/secret-sharing-erasure-coding-guide-aspiring-dropbox-decentralizer/
We can see two flaws in the above scheme. First, the justification that the challenge-response protocol will work is rather iffy at best, and has poor degenerate-case behavior: a chain takeover attack combined with a denial of service attack preventing challenges could potentially force an invalid block into a chain, requiring an eventual day-long revert of the entire chain when (if?) the smoke clears. There is also a fragility component here: an invalid block in any substate will invalidate all subsequent blocks in all substates. Second, cross-substate messages must still be seen by all nodes. We start off by solving the second problem, then proceed to show a possible defense to make the first problem slightly less bad, and then finally get around to solving it completely, and at the same time getting rid of proof of work.
The second flaw, the expensiveness of cross-substate messages, we solve by converting the blockchain model from this:
To this:

Except the cube should have twelve dimensions instead of three. Now, the protocol looks as follows:
- There exist 2N substates, each of which is identified by a binary string of length N (eg.
0010111111101). We define the Hamming distanceH(S1, S2)as the number of digits that are different between the IDs of substatesS1andS2(eg.HD(00110, 00111) = 1,HD(00110, 10010) = 2, etc). - The state of each substate stores the ordinary state tree as before, but also an outbox.
- There exists an opcode,
CROSS_SEND, which takes 4 arguments[dest_substate, to_address, value, data], and registers a message with those arguments in the outbox ofS_fromwhereS_fromis the substate from which the opcode was called - All miners must “mine an edge”; that is, valid blocks are blocks which modify two adjacent substates
S_aandS_b, and can include transactions for either substate. The block-level state transition function is as follows:- Process all transactions in order, applying the state transitions to
S_aorS_bas needed. - Process all messages in the outboxes of
S_aandS_bin order. If the message is in the outbox ofS_aand has final destinationS_b, process the state transitions, and likewise for messages fromS_btoS_a. Otherwise, if a message is inS_aandHD(S_b, msg.dest) < HD(S_a, msg.dest), move the message from the outbox ofS_ato the outbox ofS_b, and likewise vice versa.
- Process all transactions in order, applying the state transitions to
- There exists a header chain keeping track of all headers, allowing all of these blocks to be merge-mined, and keeping one centralized location where the roots of each state are stored.
Essentially, instead of travelling through the hub, messages make their way around the substates along edges, and the constantly reducing Hamming distance ensures that each message always eventually gets to its destination.
The key design decision here is the arrangement of all substates into a hypercube. Why was the cube chosen? The best way to think of the cube is as a compromise between two extreme options: on the one hand the circle, and on the other hand the simplex (basically, 2N-dimensional version of a tetrahedron). In a circle, a message would need to travel on average a quarter of the way across the circle before it gets to its destination, meaning that we make no efficiency gains over the plain old hub-and-spoke model.
In a simplex, every pair of substates has an edge, so a cross-substate message would get across as soon as a block between those two substates is produced. However, with miners picking random edges it would take a long time for a block on the right edge to appear, and more importantly users watching a particular substate would need to be at least light clients on every other substate in order to validate blocks that are relevant to them. The hypercube is a perfect balance – each substate has a logarithmically growing number of neighbors, the length of the longest path grows logarithmically, and block time of any particular edge grows logarithmically.
Note that this algorithm has essentially the same flaws as the hub-and-spoke approach – namely, that it has bad degenerate-case behavior and the economics of challenge-response protocols are very unclear. To add stability, one approach is to modify the header chain somewhat.
Right now, the header chain is very strict in its validity requirements – if any block anywhere down the header chain turns out to be invalid, all blocks in all substates on top of that are invalid and must be redone. To mitigate this, we can require the header chain to simply keep track of headers, so it can contain both invalid headers and even multiple forks of the same substate chain. To add a merge-mining protocol, we implement exponential subjective scoring but using the header chain as an absolute common timekeeper. We use a low base (eg. 0.75 instead of 0.99) and have a maximum penalty factor of 1 / 2N to remove the benefit from forking the header chain; for those not well versed in the mechanics of ESS, this basically means “allow the header chain to contain all headers, but use the ordering of the header chain to penalize blocks that come later without making this penalty too strict”. Then, we add a delay on cross-substate messages, so a message in an outbox only becomes “eligible” if the originating block is at least a few dozen blocks deep.
Proof of Stake
Now, let us work on porting the protocol to nearly-pure proof of stake. We’ll ignore nothing-at-stake issues for now; Slasher-like protocols plus exponential subjective scoring can solve those concerns, and we will discuss adding them in later. Initially, our objective is to show how to make the hypercube work without mining, and at the same time partially solve the fragility problem. We will start off with a proof of activity implementation for multichain. The protocol works as follows:
- There exist 2N substates indentified by binary string, as before, as well as a header chain (which also keeps track of the latest state root of each substate).
- Anyone can mine an edge, as before, but with a lower difficulty. However, when a block is mined, it must be published alongside the complete set of Merkle tree proofs so that a node with no prior information can fully validate all state transitions in the block.
- There exists a bonding protocol where an address can specify itself as a potential signer by submitting a bond of size
B(richer addresses will need to create multiple sub-accounts). Potential signers are stored in a specialized contractC[s]on each substates. - Based on the block hash, a random 200 substates
s[i]are chosen, and a search index0 <= ind[i] < 2^160is chosen for each substate. Definesigner[i]as the owner of the first address inC[s[i]]after indexind[i]. For the block to be valid, it must be signed by at least 133 of the setsigner[0] ... signer[199].
To actually check the validity of a block, the consensus group members would do two things. First, they would check that the initial state roots provided in the block match the corresponding state roots in the header chain. Second, they would process the transactions, and make sure that the final state roots match the final state roots provided in the header chain and that all trie nodes needed to calculate the update are available somewhere in the network. If both checks pass, they sign the block, and if the block is signed by sufficiently many consensus group members it gets added to the header chain, and the state roots for the two affected blocks in the header chain are updated.
And that’s all there is to it. The key property here is that every block has a randomly chosen consensus group, and that group is chosen from the global state of all account holders. Hence, unless an attacker has at least 33% of the stake in the entire system, it will be virtually impossible (specifically, 2-70 probability, which with 230 proof of work falls well into the realm of cryptographic impossiblity) for the attacker to get a block signed. And without 33% of the stake, an attacker will not be able to prevent legitimate miners from creating blocks and getting them signed.
This approach has the benefit that it has nice degenerate-case behavior; if a denial-of-service attack happens, then chances are that almost no blocks will be produced, or at least blocks will be produced very slowly, but no damage will be done.
Now, the challenge is, how do we further reduce proof of work dependence, and add in blockmaker and Slasher-based protocols? A simple approach is to have a separate blockmaker protocol for every edge, just as in the single-chain approach. To incentivize blockmakers to act honestly and not double-sign, Slasher can also be used here: if a signer signs a block that ends up not being in the main chain, they get punished. Schelling point effects ensure that everyone has the incentive to follow the protocol, as they guess that everyone else will (with the additional minor pseudo-incentive of software defaults to make the equilibrium stronger).
A full EVM
These protocols allow us to send one-way messages from one substate to another. However, one way messages are limited in functionality (or rather, they have as much functionality as we want them to have because everything is Turing-complete, but they are not always the nicest to work with). What if we can make the hypercube simulate a full cross-substate EVM, so you can even call functions that are on other substates?
As it turns out, you can. The key is to add to messages a data structure called a continuation. For example, suppose that we are in the middle of a computation where a contract calls a contract which creates a contract, and we are currently executing the code that is creating the inner contract. Thus, the place we are in the computation looks something like this:
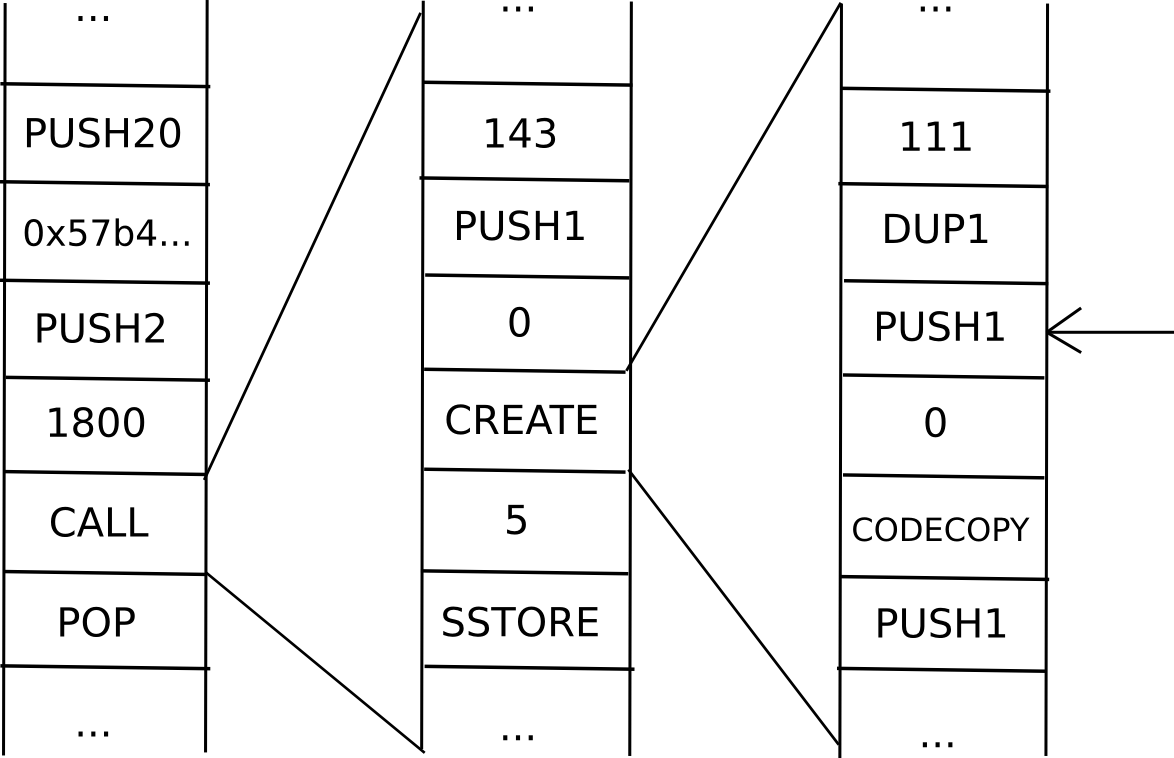
Now, what is the current “state” of this computation? That is, what is the set of all the data that we need to be able to pause the computation, and then using the data resume it later on? In a single instance of the EVM, that’s just the program counter (ie. where we are in the code), the memory and the stack. In a situation with contracts calling each other, we need that data for the entire “computational tree”, including where we are in the current scope, the parent scope, the parent of that, and so forth back to the original transaction:
This is called a “continuation”. To resume an execution from this continuation, we simply resume each computation and run it to completion in reverse order (ie. finish the innermost first, then put its output into the appropriate space in its parent, then finish the parent, and so forth). Now, to make a fully scalable EVM, we simply replace the concept of a one-way message with a continuation, and there we go.
Of course, the question is, do we even want to go this far? First of all, going between substates, such a virtual machine would be incredibly inefficient; if a transaction execution needs to access a total of ten contracts, and each contract is in some random substate, then the process of running through that entire execution will take an average of six blocks per transmission, times two transmissions per sub-call, times ten sub-calls – a total of 120 blocks. Additionally, we lose synchronicity; if A calls B then C, and B and C both call D, it’s entirely possible for C’s call of D to reach D before B’s does. Finally, it’s difficult to combine this mechanism with the concept of reverting transaction execution if transactions run out of gas. Thus, it may be easier to not bother with continuations, and rather opt for simple one-way messages; because the language is Turing-complete continuations can always be built on top.
As a result of the inefficiency and instability of cross-chain messages no matter how they are done, most dapps will want to live entirely inside of a single sub-state, and dapps or contracts that frequently talk to each other will want to live in the same sub-state as well. To prevent absolutely everyone from living on the same sub-state, we can have the gas limits for each substate “spill over” into each other and try to remain similar across substates; then, market forces will naturally ensure that popular substates become more expensive, encouraging marginally indifferent users and dapps to populate fresh new lands.
Not So Fast
So, what problems remain? First, there is the data availability problem: what happens when all of the full nodes on a given sub-state disappear? If such a situation happens, the sub-state data disappears forever, and the blockchain will essentially need to be forked from the last block where all of the sub-state data actually is known. This will lead to double-spends, some broken dapps from duplicate messages, etc. Hence, we need to essentially be sure that such a thing will never happen. This is a 1-of-N trust model; as long as one honest node stores the data we are fine. Single-chain architectures also have this trust model, but the concern increases when the number of nodes expected to store each piece of data decreases – as it does here by a factor of 2048. The concern is mitigated by the existence of altruistic nodes including blockchain explorers, but even that will become an issue if the network scales up so much that no single data center will be able to store the entire state.
Second, there is a fragility problem: if any block anywhere in the system is mis-processed, then that could lead to ripple effects throughout the entire system. A cross-substate message might not be sent, or might be re-sent; coins might be double-spent, and so forth. Of course, once a problem is detected it would inevitably be detected, and it could be solved by reverting the whole chain from that point, but it’s entirely unclear how often such situations will arise. One fragility solution is to have a separate version of ether in each substate, allowing ethers in different substates to float against each other, and then add message redundancy features to high-level languages, accepting that messages are going to be probabilistic; this would allow the number of nodes verifying each header to shrink to something like 20, allowing even more scalability, though much of that would be absorbed by an increased number of cross-substate messages doing error-correction.
A third issue is that the scalability is limited; every transaction needs to be in a substate, and every substate needs to be in a header that every node keeps track of, so if the maximum processing power of a node is N transactions, then the network can process up to N2 transactions. An approach to add further scalability is to make the hypercube structure hierarchical in some fashion – imagine the block headers in the header chain as being transactions, and imagine the header chain itself being upgraded from a single-chain model to the exact same hypercube model as described here – that would give N3 scalability, and applying it recursively would give something very much like tree chains, with exponential scalability – at the cost of increased complexity, and making transactions that go all the way across the state space much more inefficient.
Finally, fixing the number of substates at 4096 is suboptimal; ideally, the number would grow over time as the state grew. One option is to keep track of the number of transactions per substate, and once the number of transactions per substate exceeds the number of substates we can simply add a dimension to the cube (ie. double the number of substates). More advanced approaches involve using minimal cut algorithms such as the relatively simple Karger’s algorithm to try to split each substate in half when a dimension is added. However, such approaches are problematic, both because they are complex and because they involve unexpectedly massively increasing the cost and latency of dapps that end up accidentally getting cut across the middle.
Alternative Approaches
Of course, hypercubing the blockchain is not the only approach to making the blockchain scale. One very promising alternative is to have an ecosystem of multiple blockchains, some application-specific and some Ethereum-like generalized scripting environments, and have them “talk to” each other in some fashion – in practice, this generally means having all (or at least some) of the blockchains maintain “light clients” of each other inside of their own states. The challenge there is figuring out how to have all of these chains share consensus, particularly in a proof-of-stake context. Ideally, all of the chains involved in such a system would reinforce each other, but how would one do that when one can’t determine how valuable each coin is? If an attacker has 5% of all A-coins, 3% of all B-coins and 80% of all C-coins, how does A-coin know whether it’s B-coin or C-coin that should have the greater weight?
One approach is to use what is essentially Ripple consensus between chains – have each chain decide, either initially on launch or over time via stakeholder consensus, how much it values the consensus input of each other chain, and then allow transitivity effects to ensure that each chain protects every other chain over time. Such a system works very well, as it’s open to innovation – anyone can create new chains at any point with arbitrarily rules, and all the chains can still fit together to reinforce each other; quite likely, in the future we may see such an inter-chain mechanism existing between most chains, and some large chains, perhaps including older ones like Bitcoin and architectures like a hypercube-based Ethereum 2.0, resting on their own simply for historical reasons. The idea here is for a truly decentralized design: everyone reinforces each other, rather than simply hugging the strongest chain and hoping that that does not fall prey to a black swan attack.
The post Scalability, Part 2: Hypercubes appeared first on ethereum blog.
Who are you?
I’m Gav – together with Jeffrey Wilcke and Vitalik Buterin, I’m one third of the ultimate leadership of Ethereum ÐΞV. ÐΞV is a UK software firm that is under a non-profit-making agreement with the Ethereum Foundation to create version 1.0 of the Web Three software stack. We three directors—who are ultimately responsible that the software is built and works—are the same three developers who designed and implemented the first working versions of the Ethereum clients.
ÐΞV is geographically split between London (where our comms operation is based) and Berlin (which hosts the main hub of ÐΞV). Though I’m based in Zug, Switzerland (being an Ethereum employee), I have been involved most recently in putting together the Berlin side of things.
Since its inception in summer, we have been working to set up the technical side of the project, under which we include our communications, education and adoption team lead by Stephan Tual and helped by Mathias Grønnebæk for the organisation of operations.
A Berlin Who’s Who
Aeron Buchanan, though originally brought on as a mathematical modeller, has been very successful in coordinating Berlin’s various operations including helping set up the arduous process of getting a bank account, recruitment, financial juggling to get people paid, technical interviews and other tedious administration tasks; more recently he has also been helping sort out the UK side of things, too.
I must acknowledge Brian Fabian Crane who helped connect us while in Berlin and made it possible for us to have a legal structure in place quickly. At present, the operation in Berlin is directed by our major PyEthereum contributor, Heiko Hees, with Aeron being the essential point of control for all operations. Over time, we expect Aeron to get back to modelling and to find a suitable candidate for the day-to-day management of the hub.
During our time in Berlin we’ve been very active in hiring (which as a process is considerably more arduous that you might think): Alex Leverington was our first hire and he flew to Berlin all the way from Texas to join the team. Alex has been engaged helping out with the Mac builds and making volunteer contributions since early in the year, so it’s great that he wanted to step forward into a permanent role. Now Alex has been working on some of the internals of the C++ client (specifically the client multiplexing, allowing multiple Web Three applications to coexist on the same physical machine).
Over the past few months we’ve recruited a few more people: Dr. Christian Reißweiner and Christoph Jentszch joined not long ago. Christian, who holds a PhD in Multiobjective Optimization and Language Equations is now engaged in prototyping and implementing the new domain-specific contract-authoring language that I proposed a while ago, Solidity. It didn’t take me long to realise that Christoph, currently finishing his PhD in physics and who utterly loves writing unit tests, would be a great hire for sorting out our clients’ interoperability issues. He has been leading our recent surge in getting the protocol in alignment for all clients through a comprehensive code-covering set of unit tests for the virtual machine operation.
Our newest recruit, Marek Kotewicz, journeying to Berlin from Poland, was an early Ethereum volunteer and enjoyed making contracts on some early C++ client prototypes. Coming from a Web-technology background (though being perfectly competent in C++), he has now started working on our C++/Javascript API, aiming towards full node.js integration to facilitate backend integration with existing web sites. Working alongside Marek is Marian Oancea, the feathers in whose cap include much of the technical prowess behind the highly successful ether sale. He has been developing out some of the first Web apps to use Ethereum as its backend.
I look forward to welcoming three more hires in the coming weeks, including some personnel with rather impressive and uniquely relevant backgrounds. More news on that next time.
And More…
Back in London, we’ve hired design outfit Proof-of-Work, headed by Louis Chang, to put together our new website and brand. We’re ecstatic with how things are coming along there and look forward to unveiling it soon. Once this is in place we’ll have a much clearer way of getting our updates and information out regarding what’s happening at ÐΞV.
Externally to ÐΞV but supported by it are a number of other individuals and projects: I am very grateful to Tim Hughes, who continues to consult on our efforts at an ASIC-resistant proof-of-work algorithm, also implementing it in C++. Similarly, Caktux an early volunteer and maintainer of the Ncurses-based C++ Ethereum front-end neth has been invaluble (alongside Joris and Nick Savers) in getting a continuous integration system up and running. We are pleased to support both of them in their endeavours to make this project a success.
Furthermore the guys at IMAPP, a software firm in Warsaw specialising in advanced languages and compilers deserve a great nod for their on-going efforts at using their considerable expertise in implementing a just-in-time (JIT) compiled version of the Ethereum virtual machine and making computationally-complex contracts a reasonably affordable possibility.
Finally, I must thank the EthereumJ (Java client) volunteer developers Roman Mandeleil and Nick Savers, both of whom have visited us in our prototype hub here in Berlin, and who work tirelessly to find different and innovative new ways of interpreting the formal protocol specification.
The California Connection
Over in Silicon Valley, we have made two hires, Joseph Chow and Martin Becze; Joseph will be leading the efforts there and concentrating on developing some of our core Ðapps that will help demonstrate the potential of Ethereum. Martin is leading the effort to create a pure Javascript implementation of Ethereum, a lofty goal, and thus all the more impressive that the project now has a core that is compatible with PoC-6.
We are also looking forward to working with the Agreemint Foundation (ie. Mintchalk), with their effort to create an online contract development environment, to provide a simple and highly accessible interface for the beginner and intermediate level users to learn about contract development and create and deploy Web Three Ðapps.
In the future we hope to expand our operations there, particularly over January and February when Vitalik and I will be staying there, we in particular look forward to spending some time discussing the future of data sharing and online publication with Juan of IPFS and are optimistic about the possibility of finding some synergy between our projects.
On Go-ing Development
Though I’m sure Jeff will make his own post on the goings-on over at his Golang-orientated end, I will say that on a personal note I’m very happy that Alex van de Sande (aka avsa) has joined us on a permanent basis. Alex is well known on the Ethereum forums and his mockups of what Web Three could look like were simply incredible in insight, technical knowledge and polish. As an accomplished UI & UX engineer, he’ll be joining Jeff in taking Mist, the Web Three browser, forward and making it into what I am sure will simultaneously be the most revolutionary and pleasing to use piece of new software in a very long time.
So what’s happening in Berlin then?
When we arrived at first we needed somewhere to be based out of: thanks to Brian, we were invited to the Rainmaking Loft, an excellent space for tech startups that need somewhere to spread their rug prior to world domination. Since August we’ve had a nice big desk there for our developers to work alongside our inimitable location scout, hub outfitter, project manager and interior designer rolled into one; Sarah O’Neill.
Sarah has worked tirelessly in finding our perfect location, our perfect contractors and our perfect fixtures and fittings and making it actually work. Right now as I write this at 4am EEST, she’s probably up on eBay looking for a decent deal for office chairs or costing a well-placed dry wall. And what a job she has done thus far. We will be based in probably the most perfect place we could hope for. Walking distance to two U-bahn stations, we’re located on a quiet street adjacent to Oranienstraße and a central point of Kreuzberg. We’re a short cycle ride from the centre of Berlin’s mass and, in the opposite direction, from the beautiful canal and Neukölln. We have some lovely quiet bars and cafés on our sexy little street and the bustling new-tech area that is Kreuzberg at the end of it.
Our new hub, designed and outfitted by her will be a 250m² cross of office, homely relaxation environment and (self-service) café—a new (and German-building-law-friendly) twist on the notion of the holon. We’ll be able to host meetups and events, have a great area for working and have ample collaboration space for any other Ethereum-aligned operations that would prefer not to pay coffee-tax for their power & wifi.
Not to be forgotten, helping Aeron and me with administration, procurements and organisation, not to mention general German-speaking tasks, Lisa Ottosson has been invaluable during this period.
And what have we been doing?
Since beginning, ÐΞV’s time has inevitably been wast^H^H^H^H spent wisely in bureaucracy, administration and red tape. It is impressive how much of a pain doing business in a perfectly well developed nation like Germany can be. Slowly (and thanks in no small part to Aeron) this tediousness is starting to let up. When not engaged in such matters, we’ve been pressing to get our most recent proof-of-concept releases out, PoC-5 and PoC-6. PoC-5 brought with it a number of important alterations to the Ethereum virtual machine and the core protocol. PoC-6 brought a 4-second block time (this is just for stress-testing; for the mainet we’re aiming for a 10 second block time) and wonderfully fast parallel block-chain downloading. Furthermore we’ve been talking with various potential technology partners concerning the future of Swarm, our data distribution system, including with our good friend Juan Batiz-Benet (Vitalik & I got to know him while staying at his house in Silicon Valley for a week back in March).
Speaking at a few meetings and conferences has taken time also. In my case, the keynote speaker at both Inside Bitcoin and Latin America’s popular tech-fest Campus Party was an honour, as was the invitation to address the main hall at the wonderful University San Francisco of Quito. I hesitate to imagine the number of such engagements Vitalik has done during the same time period.
In addition to his impressive public speaking schedule, Vitalik has been putting in considerable efforts into research on potential consensus algorithms. Together with Vlad Zamfir, a number of potential approaches have been mooted over the past few weeks. Ultimately, we decided to follow the advice of some in our community, like Nick Szabo, who have urged us to focus on getting a working product off the ground and not try to make every last detail perfect before launching. In that regard, we’ve decided to move many of our more ambitious changes, including native extensions, auto-triggering events and proof of stake, into a planned future upgrade to happen around mid-to-late 2015.
However, during a two-week visit to London Vitalik made major progress working with Vlad on developing stable proof-of-stake consensus algorithms, and we have a few models that we think are likely to work and solve all of the problems inherent in current approaches. The two have also begun more thoroughly laying the plans for our upcoming upgrades in scalability.
More recently, I have been hard at work rewriting much of the networking code and altering the network protocol to truly split off the peer-to-peer portion of the code to make an abstract layer for all peer-to-peer applications, including those external to the Web Three project that wish to piggyback on the Ethereum peer network. I’ve also been getting PoC-7 up to scratch and more reliable, as well as upgrading my team’s development processes which predictably were becoming a little too informal for an increasingly large team. We’ll be moving towards a peer-reviewed (rather than Gav-reviewed) commit review process, we have a much more curated GitHub issue tracker, alongside an increasingly scrum-oriented project management framework (a switch to Pivotal Tracker is underway – everything public, of course). Most recently I’ve been working on the Whisper project, designing, developing, chewing things over and prototyping.
Finally, we’ve also been making inroads into some well-known and some other not-so-well-known firms that can help us make our final core software as safe and secure as humanly possible. I’m sorry I can’t go into anything more specific now, but rest assured, this is one of our priorities.
So there you have it. What’s been happening.
And what’s going to happen?
Aside from the continuing hiring process and our inroads into setting up a solid security audit, we will very soon be instituting a more informal manner for volunteers and contributors to be supported by the project. In the coming days we will be launching a number of ÐΞV schemes to make it possible for dedicated and productive members of the Ethereum and Web Three community to apply for bursaries and expenses for visiting us at one of our hub locations. Watch this space.
In terms of coding, ÐΞV, at present, has one mission: the completion of version 1.0 of the Ethereum client software which will enable the release of the genesis block. This will be done as soon as possible, though we will release the genesis block only when we (and many others in the security world) are happy that it is safe to do so: we are presently aiming to have it out sometime during this winter (i.e. between December 21st and March 21st). This will include at least a basic contract development environment (the focus of the work here in Berlin under myself), an advanced client based around Google’s Chromium browser technology and several core Ðapps (the focus of the work under Jeff), and various command-line tools.
In specifics, after we have PoC-7 out, we’ll be making at most one more proof-of-concept release before freezing the protocol and moving into our alpha release series. The first alpha will signal the end of our core refactoring & optimisation process and the beginning of our security audit; we aim to have this under way within the next 4-6 weeks. The security audit will involve a number of people and firms, both internal and external, both hired and incentivised, analysing the design and implementations looking for flaws, bugs and potential attack vectors. Once all parties involved have signed off on all aspects of the system will we move to organise a coordinated release of the final block chain. We expect the auditing process to take 2-3 months, with another couple of weeks to coordinate the final release.
During this process we will be developing out the other parts of the project, including the Whisper messaging protocol, the contract development environment and Solidity, the Ethereum browser, Mist and the core Ðapps, all in readiness for the genesis block release.
We will take a very much fluid attitude to software development & release and incrementally roll out updates and improvements to our core suite of software over time. We don’t want to keep you waiting with the release of the blockchain and so that is our development priority. So you may be assured, it will be released just as soon as it is ready.
So hold on to your hats! You’ll be coding contracts and hacking society into new forms before you know it.
Gav.
The post Gav’s ÐΞV Update I: Where Ethereum’s at appeared first on ethereum blog.
Insbesondere im Payment-Bereich fürchten die Institute, dass ihnen die IT-Riesen die Butter vom Brot nehmen könnten. Google Wallet, das 2011 angekündigt wurde, gilt als Bedrohung, ebenso das kürzlich vorgestellte Apple Pay. Ähnliches gilt für …
temenos – Bing News
Wie ich Ethereum London besuchteSalto.bzEthereum ist ein Softwaresystem, dass die Prinzipien von Bitcoin benutzt um kleine nicht-manipulierbare Programme auszuführen. Einmal in Ethereum eingespielt kann so ein …
ethereum – Google Blogsuche
Laut einer Umfrage des Genfer Unternehmens Temenos befürchten Banken, wegen der neuen Konkurrenz durch Technologiefirmen Kunden zu verlieren. Zwei von drei Finanzdienstleister reagieren darauf mit einer Erhöhung ihrer IT-Budgets. Zwei von drei Banken …
temenos – Bing News
Codius was developed by Ripple Labs, which also created its own digital currency called Ripple. Codius aims to be interoperable between a variety of cryptocurrency, such as Ripple and bitcoin, although it is managed by the private company. “Codius can interact with other ledgers and web services. It can work on bitcoin and it can work on any other system,” says Stefan Thomas, Ripple’s CTO…
Two U.S. banks, New Jersey-based Cross River Bank and Kansas-based CBW Bank, are set to announce their use of the Ripple currency protocol, which would allow instant and free cross-border payments on the network…
Payment network Ripple Labs just snagged is to U.S. banks closer to its goal of frictionless payments worldwide. CBW Bank and Cross River Bank, based in Kansas and New Jersey respectively, will be using Ripple to making global money transfers and payments…