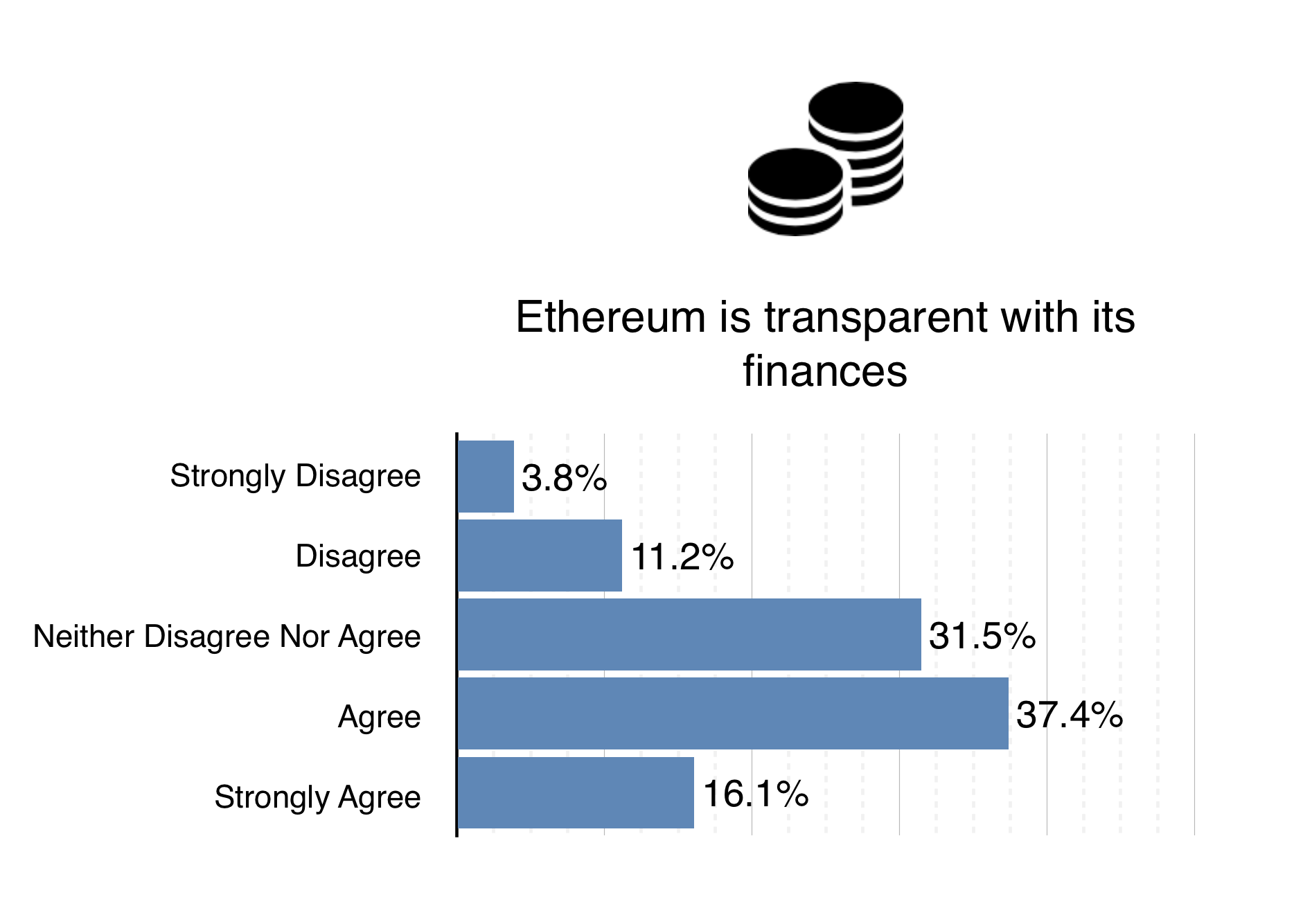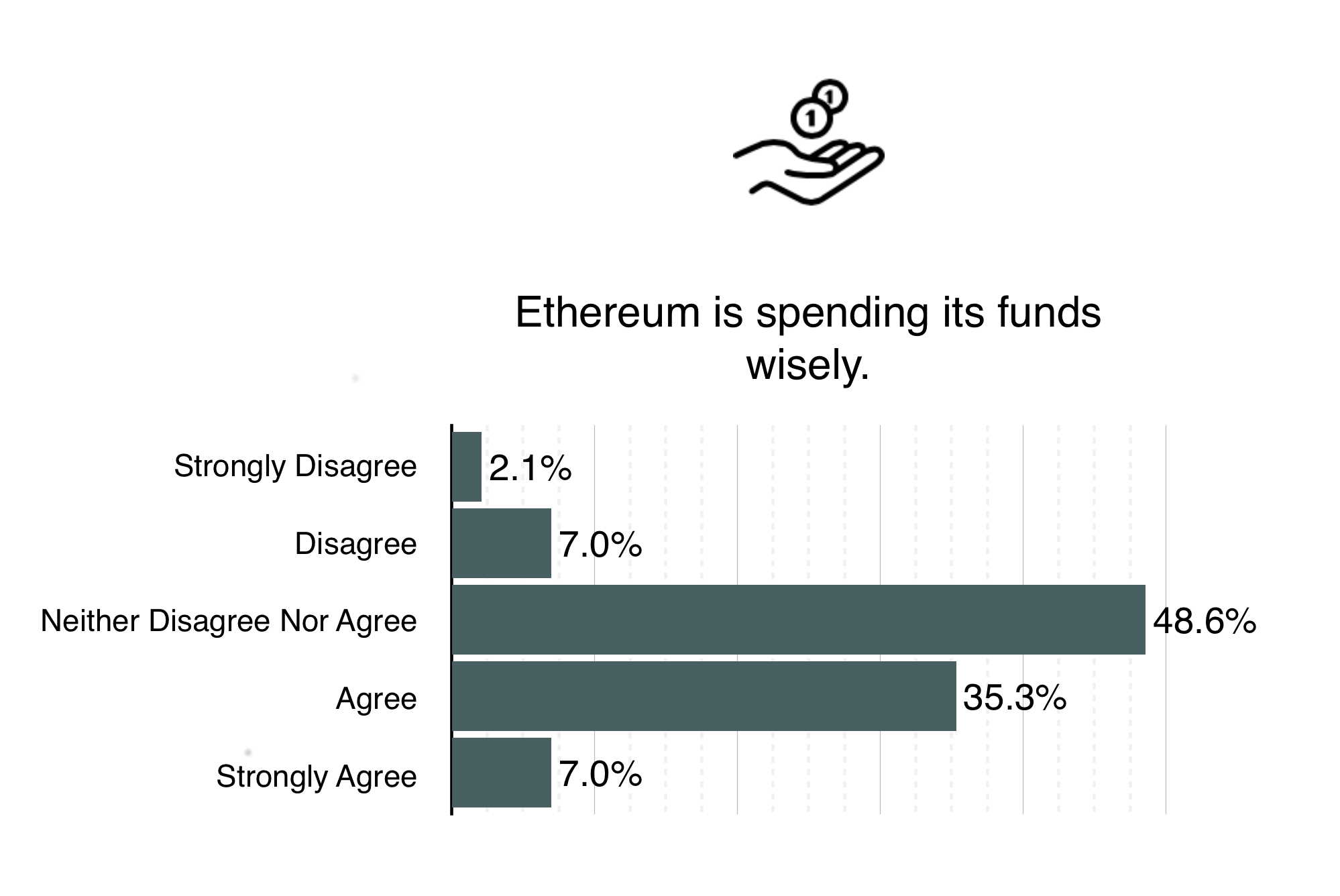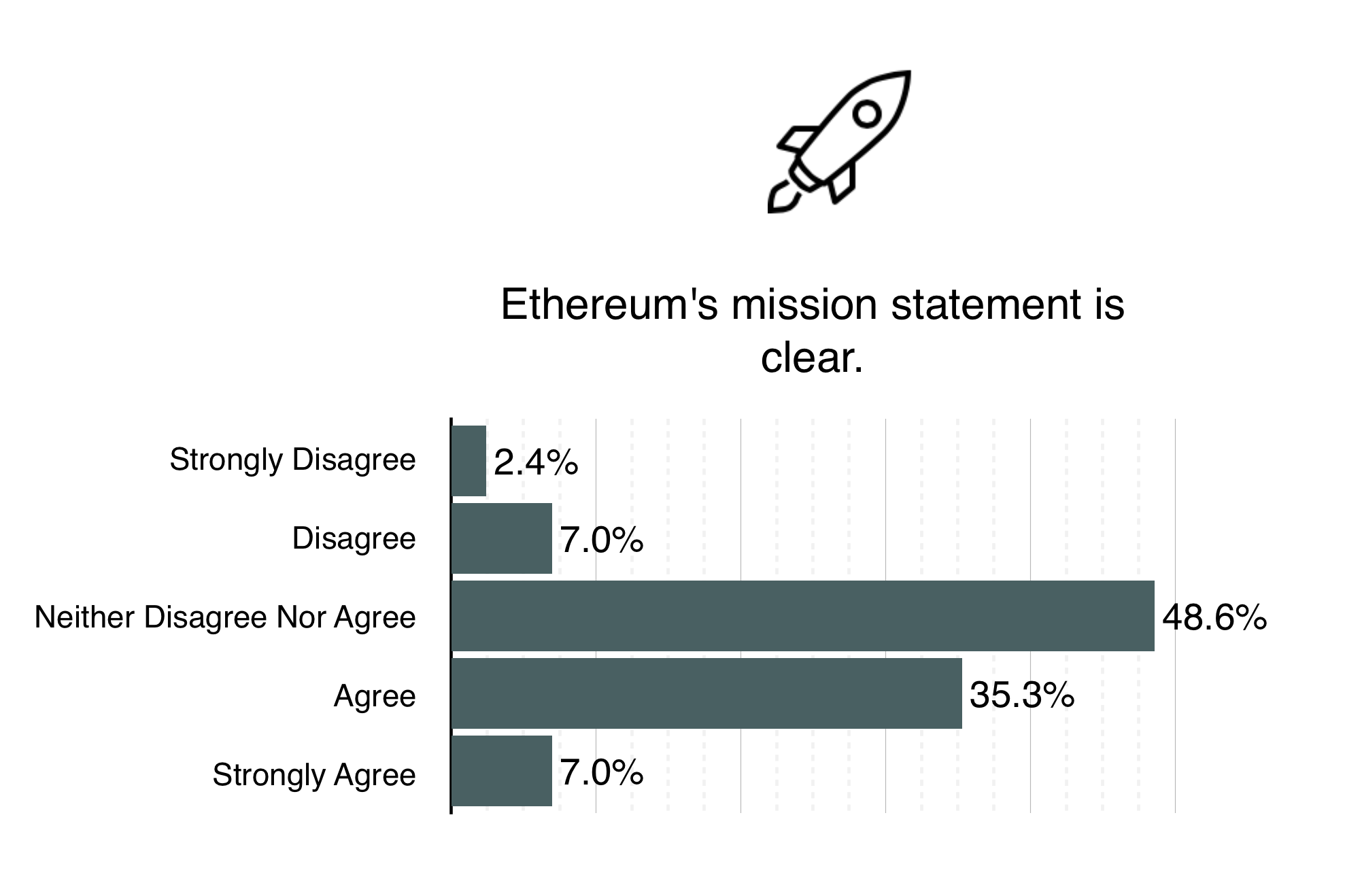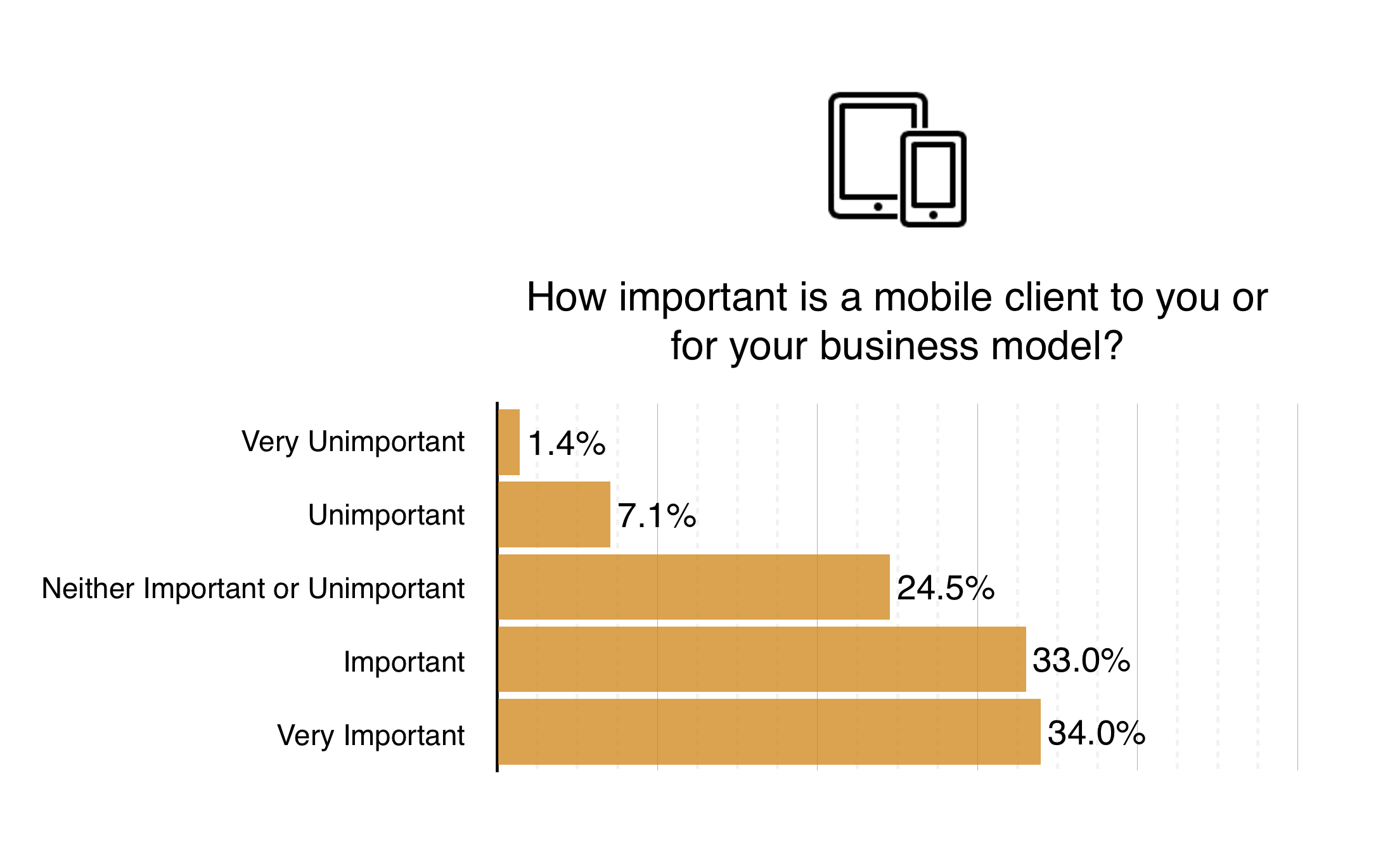Ripple Labs is thrilled to have signed its first two U.S. banks to use the Ripple protocol for real-time, cross-border payments.
Cross River Bank, an independent transaction bank based in New Jersey, and CBW Bank, a century-old institution founded in Kansas, join Fidor Bank on the Ripple network, which continues to grow.
Both banks are excited to leverage the technology in order to provide greater efficiency and innovation to their customers.
“Our business customers expect banking to move at the speed of the Web, but with the security and confidence of the traditional financial system,” said Gilles Gade, president and CEO of Cross River Bank.
“Ripple will help make that a reality, enabling our customers to instantly transfer funds internationally while meeting all compliance requirements and payments rules. We are excited to be amongst the very first banks in the U.S. to deploy Ripple as a faster, more affordable and compliant payment rail for our customers.”
“Today’s banks offer the equivalent of 300-year-old paper ledgers converted to an electronic form – a digital skin on an antiquated transaction process,” said Suresh Ramamurthi, chairman and CTO of CBW Bank.
“Ripple addresses the structural problem of payments as IP-based settlement infrastructure that powers the exchange of any types of value. We’ll now be one of the first banks in the world to offer customers a reliable, compliant, safe and secure way to instantly send and receive money internationally. As part of our integration with Ripple, we are rolling out Yantra’s cross-border, transaction-specific compliance, risk-scoring, monitoring and risk management system.”
But these new partnerships aren’t just great for Cross River Bank and CBW Bank customers, it’s great for everyone in the U.S. and Europe by essentially opening up a corridor between ACH and SEPA. Any U.S. bank can now use Cross River or CBW Bank as a correspondent to move funds in real-time to any other institution in Europe via Germany-based Fidor.
The deals will also help expand liquidity and trade volume on the protocol and generally improve the network effects of the system—which will continue to make Ripple more attractive for both market makers and developers.
Ultimately, this announcement is the culmination of many months of hard work and further validation for the Ripple Labs vision. The most exciting part? This is only just the beginning.
https://kinematec.de/wp-content/uploads/2019/10/kinematec_logo.png00christianhttps://kinematec.de/wp-content/uploads/2019/10/kinematec_logo.pngchristian2015-01-12 11:47:032015-01-12 11:47:03Ripple Labs Signs First Two US Banks
Ripple Labs has issued a Gateway Bulletin on the Partial Payment flag which describes the flag and best practices around balancing activity on and off the ledger. The tfPartialPayment flag is set by the sender to specify a payment where the beneficiary can receive less than the specified amount.
Gateways are encouraged to implement best practices and understand the Partial Payment flag to mitigate errors that can result in fraud if undetected.
https://kinematec.de/wp-content/uploads/2019/10/kinematec_logo.png00christianhttps://kinematec.de/wp-content/uploads/2019/10/kinematec_logo.pngchristian2015-01-11 19:45:042015-01-11 19:45:04Gateway Advisory On Partial Payment Flag
Chris Larsen (Co-founder and CEO) and Greg Kidd (Chief Risk Officer)—imagery courtesy of Money2020
In less than two weeks, Ripple Labs will be joining thousands of industry and thought leaders at Money20/20 in Las Vegas, Nevada.
Of the 7,000+ attendees, there will be “670 CEOs, from over 2,300 companies and 60 countries.” The team is looking forward to build on the success of Sibos earlier this month, where the Ripple narrative really picked up momentum toward industry acceptance.
Chris Larsen (Co-founder and CEO): “Remittances: Retail, Electronic & Cryptocurrencies”—Sunday, Nov. 2 at 3:00-3:45pm
If you’re interested in learning how Ripple is driving down cross-border transaction costs for banks like Fidor, please contact us at to schedule a meeting with a Ripple Labs representative.
Last Friday we did a master release of ripple-rest version 1.3.0. We’ve done a few changes externally but the substantial additions in 1.3.0 have been stability and verbose error handling. If you’ve been following the commits on [github](https://github.com/ripple/ripple-rest), we’ve also vastly improved test coverage and introduced simplicity by removing the need for Postgres.
Below is a list of some of the major changes and an explanation of the decisions we made for this last release.
Improved error handling: Error handling logic has been rewritten to provide clearer feedback for all requests. Prior to 1.3.0, an error could respond with a 200-299 range HTTP status code stating that the ripple-rest server was able to respond but the request may not have been successful. This put the burden on the developers to parse through the response body to determine whether something was successful or not. In version 1.3.0, ripple-rest will only return a “success” (200-299 range) when the actual request is successful and developers can expect that the response body will match what a successful request looks like. With actual errors and errors responses, ripple-rest will now include an error_type (a short code identifying the error), an error (a human-readable summary), and an optional message (for longer explanation of errors if needed). Details [here](http://dev.ripple.com/ripple-rest.html#errors).
DB support for SQLite on disk, and removal of Postgres support: Version 1.3.0 now directly supports both SQLite in memory and on disk. We’ve removed support for Postgres based on feedback that the installation has been a huge burden for the minimal amount of data that is stored in ripple-rest. The installation with SQLite is now much leaner and configuring a new database is as simple as pointing to a flat file location in the config.json. In the future, we may revisit adding additional database connectors for clustered and high availability deployments, but we’re much more keen on the usability and simplicity of only supporting SQLite at this point.
Config.json 2.0: The previous config.json 1.0.1 was confusing and disabling things like SSL required removal of lines inside the config file while environment variables could be set to overwrite config file values. We’ve cleaned up a lot of that messiness and we’ve modified the new config.json so that all configurations are fully transparent. SSL can be disabled simply by setting “ssl_enabled” as false and in order to switch to SQLite in memory the “db_path” should be set to “:memory:” instead of pointing to a flat file. Lastly, as a reminder to folks who didn’t know, ripple-rest does support a multi-server configuration in the array of “rippled_servers”. Documentation on config file can be found [here](https://github.com/ripple/ripple-rest/blob/develop/docs/server-configuration.md)
/v1/wallet/new endpoint: Easy and simple way to generate ripple wallets! No explanation needed!
Removed /v1/tx/{:hash} and /v1/transaction/{:hash}: Use `/v1/transactions/{:hash}`. This change serves to provide consistency with REST standards.
Removed /v1/payments: Use `/v1/accounts/{source_address}/payments` to submit a payment. This change serves to provide consistency in the payment flow.
We appreciate the continued feedback from those of you who are building integrations with ripple-rest and appreciate all the support that you’ve given us so far.
Nearly 300 Ripple enthusiasts attended Around the World in 5 Seconds.
Despite pouring rain, nearly three hundred guests attended Around the World in 5 Seconds, a special night of demos and celebration at the Ripple Labs office in downtown San Francisco, an event meant to engage the local community and share our vision of Ripple’s potential.
Attendees ranged from engineers, product managers, and senior executives from blue-chip tech, banking and consulting companies to entrepreneurs bootstrapping their own ventures.
Signing in.
A series of product demos provided developers, investors, and industry leaders a tangible, hands-on experience for understanding how the Ripple protocol facilitates faster, cheaper, and more frictionless global payments than ever before.
Learning about the intricacies of real-time settlement and the internet-of-value.
One demo station was manned by Marco Montes, who you might recognize from the newly re-designed Ripple.com homepage. Marco is the founder and CEO of Saldo.mx, a novel remittance service that allows US customers to pay bills back in Mexico using the Ripple protocol.
Ripple Labs CTO Stefan Thomas and software engineer Evan Schwartz delivered two back-to-back tech talks on Codius, an ecosystem for developing distributed applications that utilizes smart contracts, to two jam-packed and enthusiastic crowds.
Stefan and Evan explain Codius.
The presentation represents the first of a series of talks as part of our mission to better educate the broader community about Ripple technology, behind the scenes developments, as well as our take on the industry at large.
A warm thank you to all those who weathered the storm and helped make this inaugural event a resounding success. It surely won’t be the last so we look forward to seeing you at the next one, along with those who weren’t able to make it out this time.
https://kinematec.de/wp-content/uploads/2015/01/topphoto1.jpg533960christianhttps://kinematec.de/wp-content/uploads/2019/10/kinematec_logo.pngchristian2015-01-10 04:15:222015-01-11 13:08:11Event Recap: Around the World in 5 Seconds
https://kinematec.de/wp-content/uploads/2019/10/kinematec_logo.png00christianhttps://kinematec.de/wp-content/uploads/2019/10/kinematec_logo.pngchristian2015-01-10 04:15:202015-01-11 13:08:46Größte islamische Bank Indonesiens führt neues, modernes Kernbankensystem ein
Special thanks to Vlad Zamfir and Jae Kwon for many of the ideas described in this post
Aside from the primary debate around weak subjectivity, one of the important secondary arguments raised against proof of stake is the issue that proof of stake algorithms are much harder to make light-client friendly. Whereas proof of work algorithms involve the production of block headers which can be quickly verified, allowing a relatively small chain of headers to act as an implicit proof that the network considers a particular history to be valid, proof of stake is harder to fit into such a model. Because the validity of a block in proof of stake relies on stakeholder signatures, the validity depends on the ownership distribution of the currency in the particular block that was signed, and so it seems, at least at first glance, that in order to gain any assurances at all about the validity of a block, the entire block must be verified.
Given the sheer importance of light client protocols, particularly in light of the recent corporate interest in “internet of things” applications (which must often necessarily run on very weak and low-power hardware), light client friendliness is an important feature for a consensus algorithm to have, and so an effective proof of stake system must address it.
Light clients in Proof of Work
In general, the core motivation behind the “light client” concept is as follows. By themselves, blockchain protocols, with the requirement that every node must process every transaction in order to ensure security, are expensive, and once a protocol gets sufficiently popular the blockchain becomes so big that many users become not even able to bear that cost. The Bitcoin blockchain is currently 27 GB in size, and so very few users are willing to continue to run “full nodes” that process every transaction. On smartphones, and especially on embedded hardware, running a full node is outright impossible.
Hence, there needs to be some way in which a user with far less computing power to still get a secure assurance about various details of the blockchain state – what is the balance/state of a particular account, did a particular transaction process, did a particular event happen, etc. Ideally, it should be possible for a light client to do this in logarithmic time – that is, squaring the number of transactions (eg. going from 1000 tx/day to 1000000 tx/day) should only double a light client’s cost. Fortunately, as it turns out, it is quite possible to design a cryptocurrency protocol that can be securely evaluated by light clients at this level of efficiency.
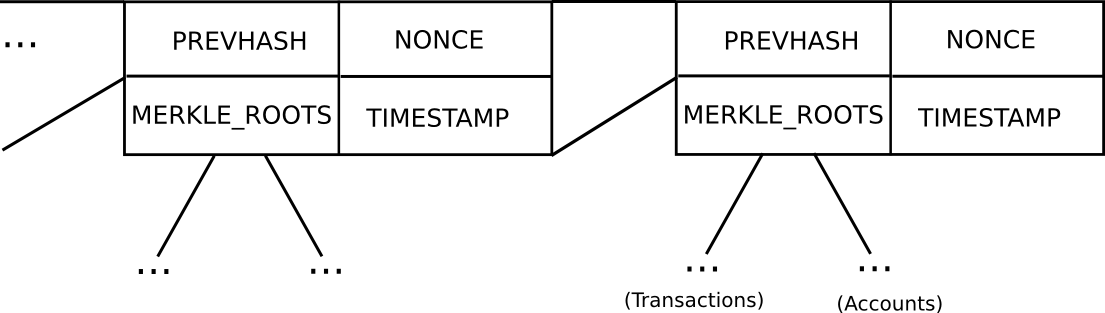
Basic block header model in Ethereum (note that Ethereum has a Merkle tree for transactions and accounts in each block, allowing light clients to easily access more data)
In Bitcoin, light client security works as follows. Instead of constructing a block as a monolithic object containing all of the transactions directly, a Bitcoin block is split up into two parts. First, there is a small piece of data called the block header, containing three key pieces of data:
The hash of the previous block header
The Merkle root of the transaction tree (see below)
The proof of work nonce
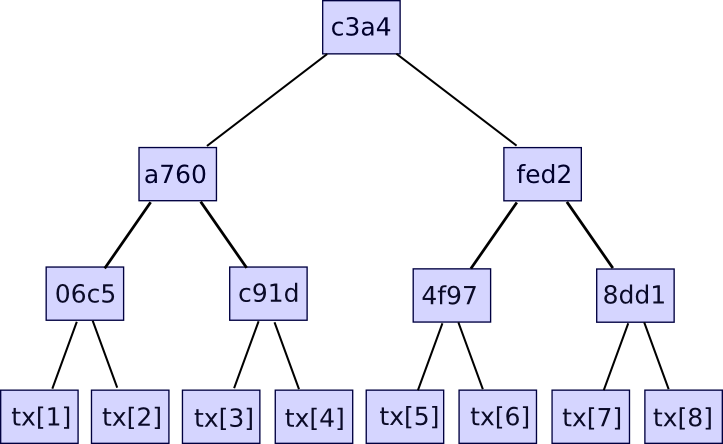
Additional data like the timestamp is also included in the block header, but this is not relevant here. Second, there is the transaction tree. Transactions in a Bitcoin block are stored in a data structure called a Merkle tree. The nodes on the bottom level of the tree are the transactions, and then going up from there every node is the hash of the two nodes below it. For example, if the bottom level had sixteen transactions, then the next level would have eight nodes: hash(tx[1] + tx[2]), hash(tx[3] + tx[4]), etc. The level above that would have four nodes (eg. the first node is equal to hash(hash(tx[1] + tx[2]) + hash(tx[3] + tx[4]))), the level above has two nodes, and then the level at the top has one node, the Merkle root of the entire tree.
The Merkle root can be thought of as a hash of all the transactions together, and has the same properties that you would expect out of a hash – if you change even one bit in one transaction, the Merkle root will end up completely different, and there is no way to come up with two different sets of transactions that have the same Merkle root. The reason why this more complicated tree construction needs to be used is that it actually allows you to come up with a compact proof that one particular transaction was included in a particular block. How? Essentially, just provide the branch of the tree going down to the transaction:
The verifier will verify only the hashes going down along the branch, and thereby be assured that the given transaction is legitimately a member of the tree that produced a particular Merkle root. If an attacker tries to change any hash anywhere going down the branch, the hashes will no longer match and the proof will be invalid. The size of each proof is equal to the depth of the tree – ie. logarithmic in the number of transactions. If your block contains 220 (ie. ~1 million) transactions, then the Merkle tree will have only 20 levels, and so the verifier will only need to compute 20 hashes in order to verify a proof. If your block contains 230 (ie. ~1 billion) transactions, then the Merkle tree will have 30 levels, and so a light client will be able to verify a transaction with just 30 hashes.
Ethereum extends this basic mechanism with a two additional Merkle trees in each block header, allowing nodes to prove not just that a particular transaction occurred, but also that a particular account has a particular balance and state, that a particular event occurred, and even that a particular account does not exist.
Verifying the Roots
Now, this transaction verification process all assumes one thing: that the Merkle root is trusted. If someone proves to you that a transaction is part of a Merkle tree that has some root, that by itself means nothing; membership in a Merkle tree only proves that a transaction is valid if the Merkle root is itself known to be valid. Hence, the other critical part of a light client protocol is figuring out exactly how to validate the Merkle roots – or, more generally, how to validate the block headers.
First of all, let us determine exactly what we mean by “validating block headers”. Light clients are not capable of fully validating a block by themselves; protocols exist for doing validation collaboratively, but this mechanism is expensive, and so in order to prevent attackers from wasting everyone’s time by throwing around invalid blocks we need a way of first quickly determining whether or not a particular block header is probably valid. By “probably valid” what we mean is this: if an attacker gives us a block that is determined to be probably valid, but is not actually valid, then the attacker needs to pay a high cost for doing so. Even if the attacker succeeds in temporarily fooling a light client or wasting its time, the attacker should still suffer more than the victims of the attack. This is the standard that we will apply to proof of work, and proof of stake, equally.
In proof of work, the process is simple. The core idea behind proof of work is that there exists a mathematical function which a block header must satisfy in order to be valid, and it is computationally very intensive to produce such a valid header. If a light client was offline for some period of time, and then comes back online, then it will look for the longest chain of valid block headers, and assume that that chain is the legitimate blockchain. The cost of spoofing this mechanism, providing a chain of block headers that is probably-valid-but-not-actually-valid, is very high; in fact, it is almost exactly the same as the cost of launching a 51% attack on the network.
In Bitcoin, this proof of work condition is simple: sha256(block_header) < 2**187 (in practice the “target” value changes, but once again we can dispense of this in our simplified analysis). In order to satisfy this condition, miners must repeatedly try different nonce values until they come upon one such that the proof of work condition for the block header is satisfied; on average, this consumes about 269 computational effort per block. The elegant feature of Bitcoin-style proof of work is that every block header can be verified by itself, without relying on any external information at all. This means that the process of validating the block headers can in fact be done in constant time – download 80 bytes and run a hash of it – even better than the logarithmic bound that we have established for ourselves. In proof of stake, unfortunately we do not have such a nice mechanism.
Light Clients in Proof of Stake
If we want to have an effective light client for proof of stake, ideally we would like to achieve the exact same complexity-theoretic properties as proof of work, although necessarily in a different way. Once a block header is trusted, the process for accessing any data from the header is the same, so we know that it will take a logarithmic amount of time in order to do. However, we want the process of validating the block headers themselves to be logarithmic as well.
To start off, let us describe an older version of Slasher, which was not particularly designed to be explicitly light-client friendly:
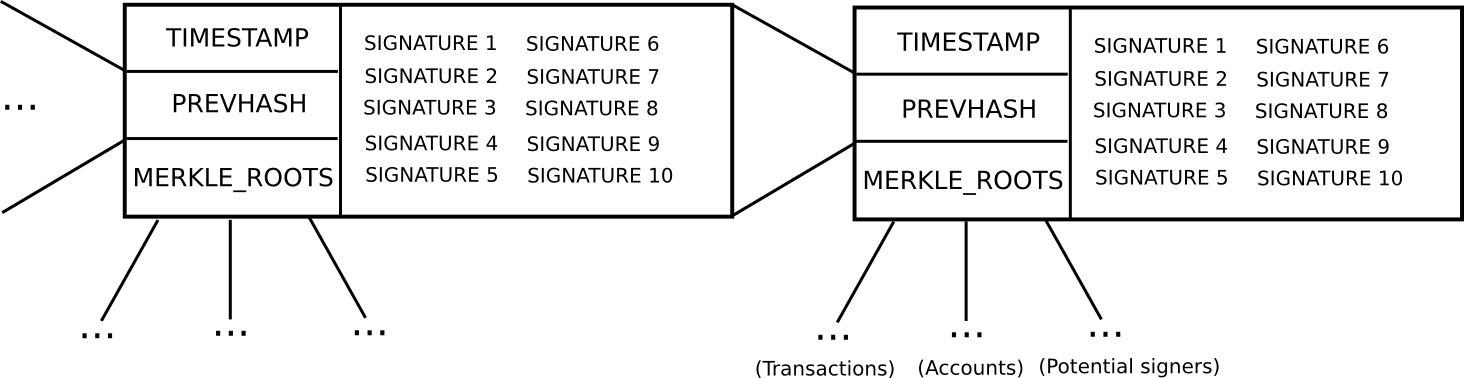
In order to be a “potential blockmaker” or “potential signer”, a user must put down a security deposit of some size. This security deposit can be put down at any time, and lasts for a long period of time, say 3 months.
During every time slot T (eg. T = 3069120 to 3069135 seconds after genesis), some function produces a random number R (there are many nuances behind making the random number secure, but they are not relevant here). Then, suppose that the set of potential signers ps (stored in a separate Merkle tree) has size N. We take ps[sha3(R) % N] as the blockmaker, and ps[sha3(R + 1) % N], ps[sha3(R + 2) % N] … ps[sha3(R + 15) % N] as the signers (essentially, using R as entropy to randomly select a signer and 15 blockmakers)
Blocks consist of a header containing (i) the hash of the previous block, (ii) the list of signatures from the blockmaker and signers, and (iii) the Merkle root of the transactions and state, as well as (iv) auxiliary data like the timestamp.
A block produced during time slot T is valid if that block is signed by the blockmaker and at least 10 of the 15 signers.
If a blockmaker or signer legitimately participates in the blockmaking process, they get a small signing reward.
If a blockmaker or signer signs a block that is not on the main chain, then that signature can be submitted into the main chain as “evidence” that the blockmaker or signer is trying to participate in an attack, and this leads to that blockmaker or signer losing their deposit. The evidence submitter may receive 33% of the deposit as a reward.
Unlike proof of work, where the incentive not to mine on a fork of the main chain is the opportunity cost of not getting the reward on the main chain, in proof of stake the incentive is that if you mine on the wrong chain you will get explicitly punished for it. This is important; because a very large amount of punishment can be meted out per bad signature, a much smaller number of block headers are required to achieve the same security margin.
Now, let us examine what a light client needs to do. Suppose that the light client was last online N blocks ago, and wants to authenticate the state of the current block. What does the light client need to do? If a light client already knows that a block B[k] is valid, and wants to authenticate the next block B[k+1], the steps are roughly as follows:
Compute the function that produces the random value R during block B[k+1] (computable either constant or logarithmic time depending on implementation)
Given R, get the public keys/addresses of the selected blockmaker and signer from the blockchain’s state tree (logarithmic time)
Verify the signatures in the block header against the public keys (constant time)
And that’s it. Now, there is one gotcha. The set of potential signers may end up changing during the block, so it seems as though a light client might need to process the transactions in the block before being able to compute ps[sha3(R + k) % N]. However, we can resolve this by simply saying that it’s the potential signer set from the start of the block, or even a block 100 blocks ago, that we are selecting from.
Now, let us work out the formal security assurances that this protocol gives us. Suppose that a light client processes a set of blocks, B[1] ... B[n], such that all blocks starting from B[k + 1] are invalid. Assuming that all blocks up to B[k] are valid, and that the signer set for block B[i] is determined from block B[i - 100], this means that the light client will be able to correctly deduce the signature validity for blocks B[k + 1] ... B[k + 100]. Hence, if an attacker comes up with a set of invalid blocks that fool a light client, the light client can still be sure that the attacker will still have to pay ~1100 security deposits for the first 100 invalid blocks. For future blocks, the attacker will be able to get away with signing blocks with fake addresses, but 1100 security deposits is an assurance enough, particularly since the deposits can be variably sized and thus hold many millions of dollars of capital altogether.
Thus, even this older version of Slasher is, by our definition, light-client-friendly; we can get the same kind of security assurance as proof of work in logarithmic time.
A Better Light-Client Protocol
However, we can do significantly better than the naive algorithm above. The key insight that lets us go further is that of splitting the blockchain up into epochs. Here, let us define a more advanced version of Slasher, that we will call “epoch Slasher”. Epoch Slasher is identical to the above Slasher, except for a few other conditions:
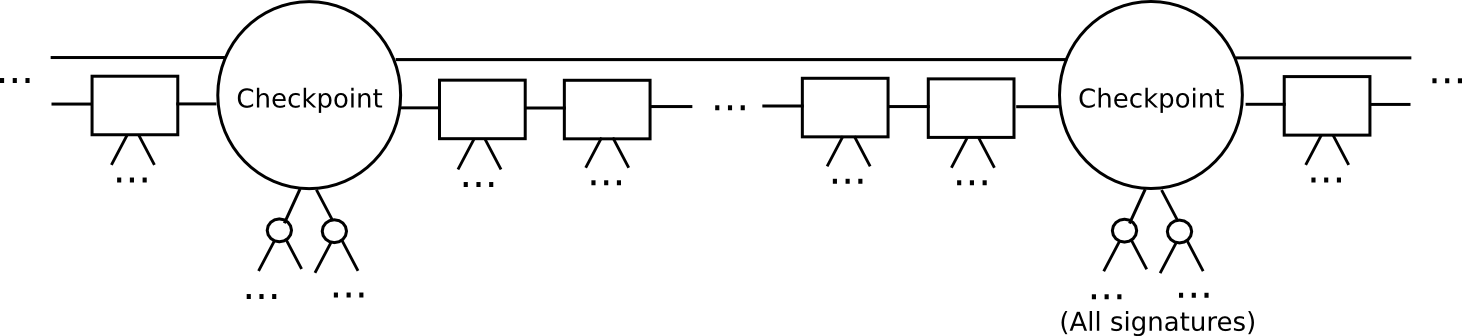
Define a checkpoint as a block such that block.number % n == 0 (ie. every n blocks there is a checkpoint). Think of n as being somewhere around a few weeks long; it only needs to be substantially less than the security deposit length.
For a checkpoint to be valid, 2/3 of all potential signers have to approve it. Also, the checkpoint must directly include the hash of the previous checkpoint.
The set of signers during a non-checkpoint block should be determined from the set of signers during the second-last checkpoint.
This protocol allows a light client to catch up much faster. Instead of processing every block, the light client would skip directly to the next checkpoint, and validate it. The light client can even probabilistically check the signatures, picking out a random 80 signers and requesting signatures for them specifically. If the signatures are invalid, then we can be statistically certain that thousands of security deposits are going to get destroyed.
After a light client has authenticated up to the latest checkpoint, the light client can simply grab the latest block and its 100 parents, and use a simpler per-block protocol to validate them as in the original Slasher; if those blocks end up being invalid or on the wrong chain, then because the light client has already authenticated the latest checkpoint, and by the rules of the protocol it can be sure that the deposits at that checkpoint are active until at least the next checkpoint, once again the light client can be sure that at least 1100 deposits will be destroyed.
With this latter protocol, we can see that not only is proof of stake just as capable of light-client friendliness as proof of work, but moreover it’s actually even more light-client friendly. With proof of work, a light client synchronizing with the blockchain must download and process every block header in the chain, a process that is particularly expensive if the blockchain is fast, as is one of our own design objectives. With proof of stake, we can simply skip directly to the latest block, and validate the last 100 blocks before that to get an assurance that if we are on the wrong chain, at least 1100 security deposits will be destroyed.
Now, there is still a legitimate role for proof of work in proof of stake. In proof of stake, as we have seen, it takes a logarithmic amount of effort to probably-validate each individual block, and so an attacker can still cause light clients a logarithmic amount of annoyance by broadcasting bad blocks. Proof of work alone can be effectively validated in constant time, and without fetching any data from the network. Hence, it may make sense for a proof of stake algorithm to still require a small amount of proof of work on each block, ensuring that an attacker must spend some computational effort in order to even slightly inconvenience light clients. However, the amount of computational effort required to compute these proofs of work will only need to be miniscule.
https://kinematec.de/wp-content/uploads/2015/01/pow_header.png3131105christianhttps://kinematec.de/wp-content/uploads/2019/10/kinematec_logo.pngchristian2015-01-10 04:15:142015-01-12 07:23:35Light Clients and Proof of Stake
Ripple Labs CTO Stefan Thomas and software engineer Evan Schwartz present Codius.
As part of an ongoing initiative to better educate the broader community about Ripple technology, behind the scenes developments, as well as our take on the industry at large, Ripple Labs will be releasing a series a tech talks, the first of which is an introduction to Codius.
The tech talk was presented by CTO Stefan Thomas and software engineer Evan Schwartz to a full house on November 20, 2014 at Around the World in 5 Seconds, a special night of demos and celebration at Ripple Labs headquarters in downtown San Francisco.
Codius is a platform developed by Ripple Labs that enables smart contracts technology. But from a broader perspective, it’s a framework for developing distributed applications, what we call “smart programs.” In this tech talk, you’ll learn about:
https://kinematec.de/wp-content/uploads/2015/01/codius1.jpg463960christianhttps://kinematec.de/wp-content/uploads/2019/10/kinematec_logo.pngchristian2015-01-09 20:23:082015-01-12 07:23:50Ripple Labs Tech Talk: An Introduction to Codius
Back in November, we created a quick survey for the Ethereum community to help us gauge how we’re doing, what can be improved, and how best we can engage with you all as we move forward towards the genesis block release in March. We feel it’s very important to enable the community to interact with Ethereum as well as itself, and we hope to offer new and exciting tools to do so using the survey results for guidance.
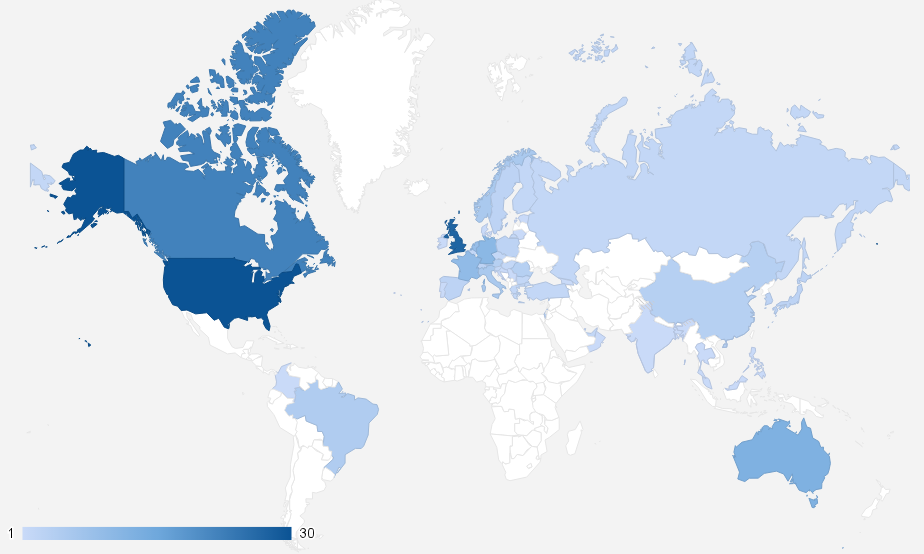
The survey itself consisted of 14 questions split into two sections; Ethereum as an “Organisation” and Ethereum as a “Technology”. There was a total of 286 responses. This represents 7.8% of the current Ethereum reddit population, or 2.4% of the current @ethereumproject followers.
What country do you currently reside in?
So, this is where everybody lives. To sum it up by continent – of the 286 respondents there are 123 (43%) in North America, 114 (40%) in Europe, 30 (10%) in Asia, 13 (5%) in Oceana and 6 (2%) in South America. No surprises there, though it does show how we – and the crypto space in general – have much work to do in areas south of the Brandt Line. One way to go about this is to seed more international Ethereum meetups. You can see a map of all the current Ethereum meetups here (We have 81 in total all over the world from London to New York to Tehran with over 6000 members taking part). If you’d like to start one yourself, please do message us and we can offer further assistance – .
It’s understood that our transparency is very important to the community. To that end, we strive to make much of our internal workings freely available on the internet. As indicated in the chart, most people agree that we are doing just that. However, more can always be done. We’re currently working on a refresh of the ethereum.org website ready for the release of the genesis block. Expect much more content and information as we complete this towards the end of January. In the meantime, have a look at the Ethereum GitHub Repository, or head over to the new ΞTH ÐΞV website for a greater understanding of the entity that is delivering Ethereum 1.0, as well as its truly incredible team.
We’ve always tried to give the community as much information about our financial situation as possible, and from the results it seems like a lot of you agree. For further information on how Ethereum intends to use the funds raised in the Ether sale as we move forward, check out the Road Map and the ĐΞV PLAN. To learn more about the Ether Sale itself, have a look at Vitalik’s Ether Sale Introduction, the Ethereum Bitcoin Wallet, or the Ether Sale Statistical Overview.
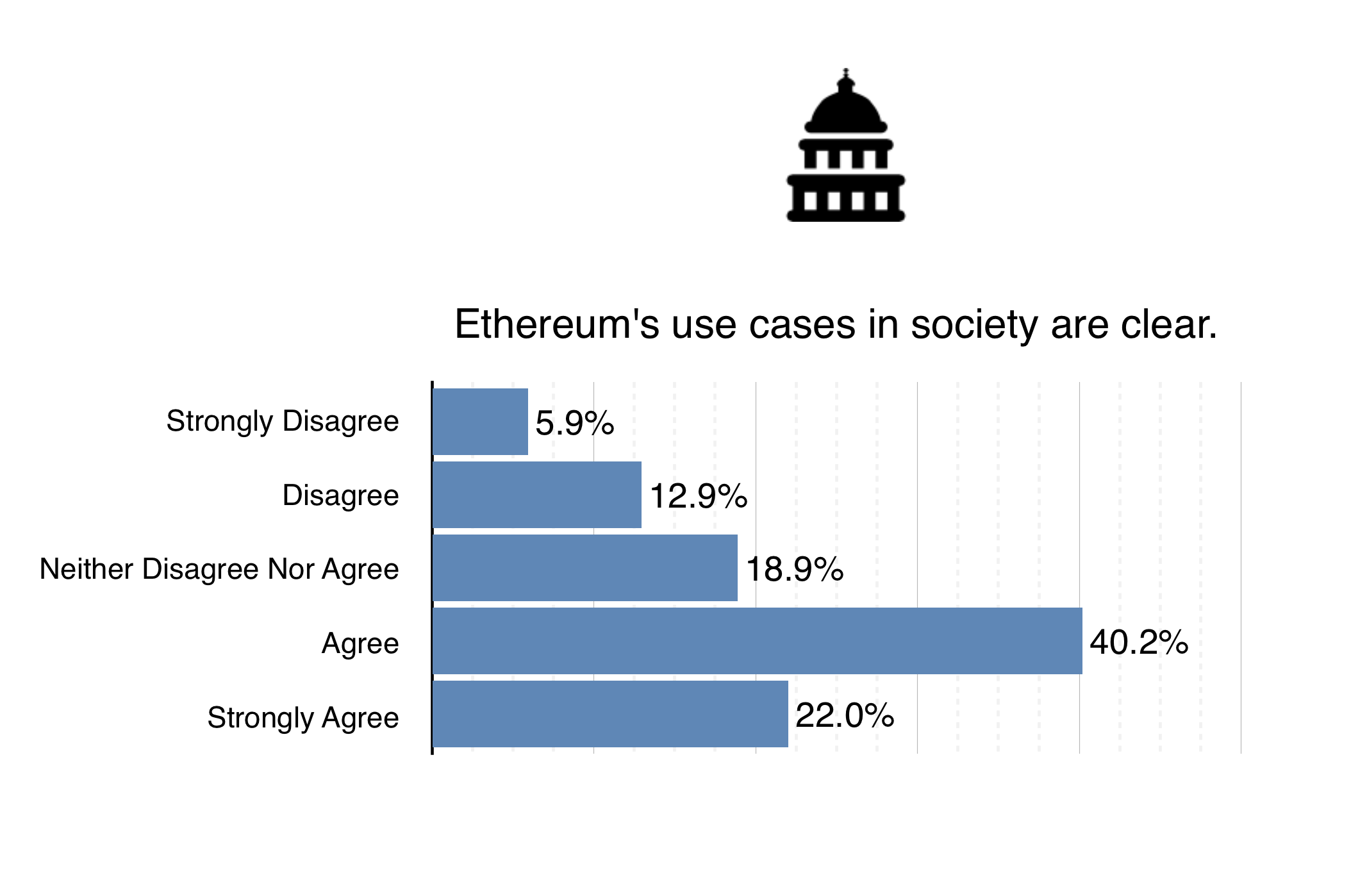
Though most people agree Ethereum’s use cases in society are clear, I wouldn’t be so sure we’ve figured them all out just yet. Everyday we’re speaking with developers and entrepreneurs via Skype or on IRC (Join in your browser – #ethereum / #ethereum-dev) who have thought of new and exciting ideas that they are looking to implement on top of Ethereum – many of which are brand new to us. For a brief overview of some of the use cases we’ve encountered, check out Stephan Tual’s recent presentation at NewFinance.
We’re doing our best to keep everyone updated with the plethora of changes, updates and general progression of the project that’s been taking place over the recent months. Gavin Wood and Jeff Wilcke especially have written some excellent blog updates on how things are going in their respective Berlin and Amsterdam ÐΞV Hubs. You can see all of the updates in the Project category of the Ethereum blog.
ΞTH ÐΞV’s mission statement is now proudly presented on the ΞTH ÐΞV website for all to see. In detail, it explains what needs to be achieved as time goes on, but can be summed up as “To research, design and build software that, as best as possible, facilitates, in a secure, decentralised and fair manner, the communication and automatically-enforced agreement between parties.”
Much like the crypto space in general, Ethereum is somewhat difficult to initially get your head around. No doubt about that, and it’s our job to make the process of gaining understanding and enabling participation as easy and intuitive as possible. As mentioned previously, the new look ethereum.org website will be an invaluable tool in helping people access the right information that is applicable to their own knowledge and skill set. Also, in time we aim to create a Udemy/Codacademy like utility which will allow people with skills ranging from none to Jedi Master to learn how Ethereum works and how to implement their ideas. In the mean time, a great place to start for those wanting to use Ethereum is Ken Kappler’s recent Tutorials.
This was an important question as it gave a lot of perspective on what aspects needed to be focused on before genesis, and what (though useful) could be developed afterwards. From a UI point of view, the Go team in Amsterdam is working towards the creation of Mist, Ethereum’s “Ðapp Navigator”. Mist’s initial design ideas are presented by the Lead UI Designer, Alex Van de Sande in this video.
Ease of installation will factor greatly in user adoption – we cant very well have people recompiling the client every time a new update is pushed! So binaries with internal update systems are in the pipeline. Client Reliability (bugs) is being actioned on by Jutta Steiner, the Manager of our internal and external security audits. We expect the community bug bounty project to be live by the middle of January, so stay tuned and be ready for epic 11 figure Satoshi rewards, leaderboards and more “1337” prizes.
Developer tools are on the way too. Specifically, project “Mix”. Mix supports some rather amazing features, including documentation, a compiler, debugger integration for writing information on code health, valid invariant, code structure and code formatting, as well as variable values and assertion truth annotations. It’s a long term project expected to be delivered in the next 12-18 months, right now we are very much focused on completing the blockchain. Once complete, we can reallocate our resources to other important projects. You can find out more in the Mix presentation from ÐΞVcon-0. For now, documentation is constantly being generated on the Ethereum GitHub Wiki.
The blog and social media interaction will continue to deliver Ethereum content on relevant channels with the aim of reaching the widest range of people as possible.
With more people owning smartphones than computers already, imagine how prolific they’ll will be as time goes on? This will be the case especially in emerging markets such as India and Nigeria, it’s likely they’ll leapfrog computers to some extent and gain wide adoption very quickly. A mobile light client will be greatly important to the usability of Ethereum. As part of IBM and Samsung’s joint project “Adept” (an IoT platform which is currently being unveiled at CES 2015), an Android version of the Ethereum Java client – ethereumj, is going to be open-sourced on GitHub. This will go a long way to getting Ethereum Mobile!
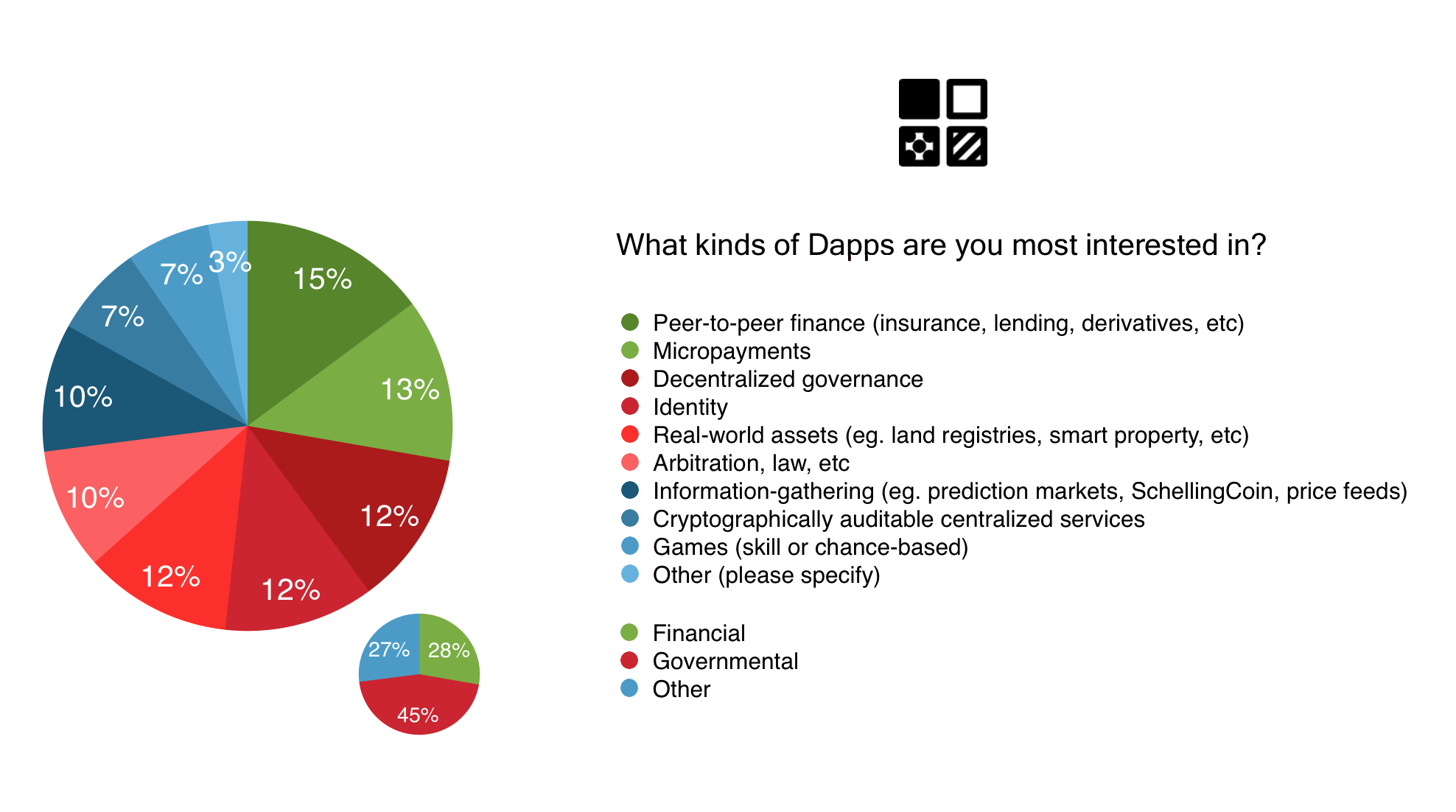
It’s interesting to see a very mixed bag of responses for this question. As was said previously, Ethereum’s use cases are as wide as they are varied, and it’s great to see how many different types of services people are looking to implement on top of Ethereum. The emphasis on governance based Ðapps highlights Ethereum’s ability to facilitate interactions between the digital and physical world and create autonomously governed communities that can compete with both governments and corporations. Primavera De Filippi and Raffaele Mauro investigate this further in the Internet Policy Review Journal.
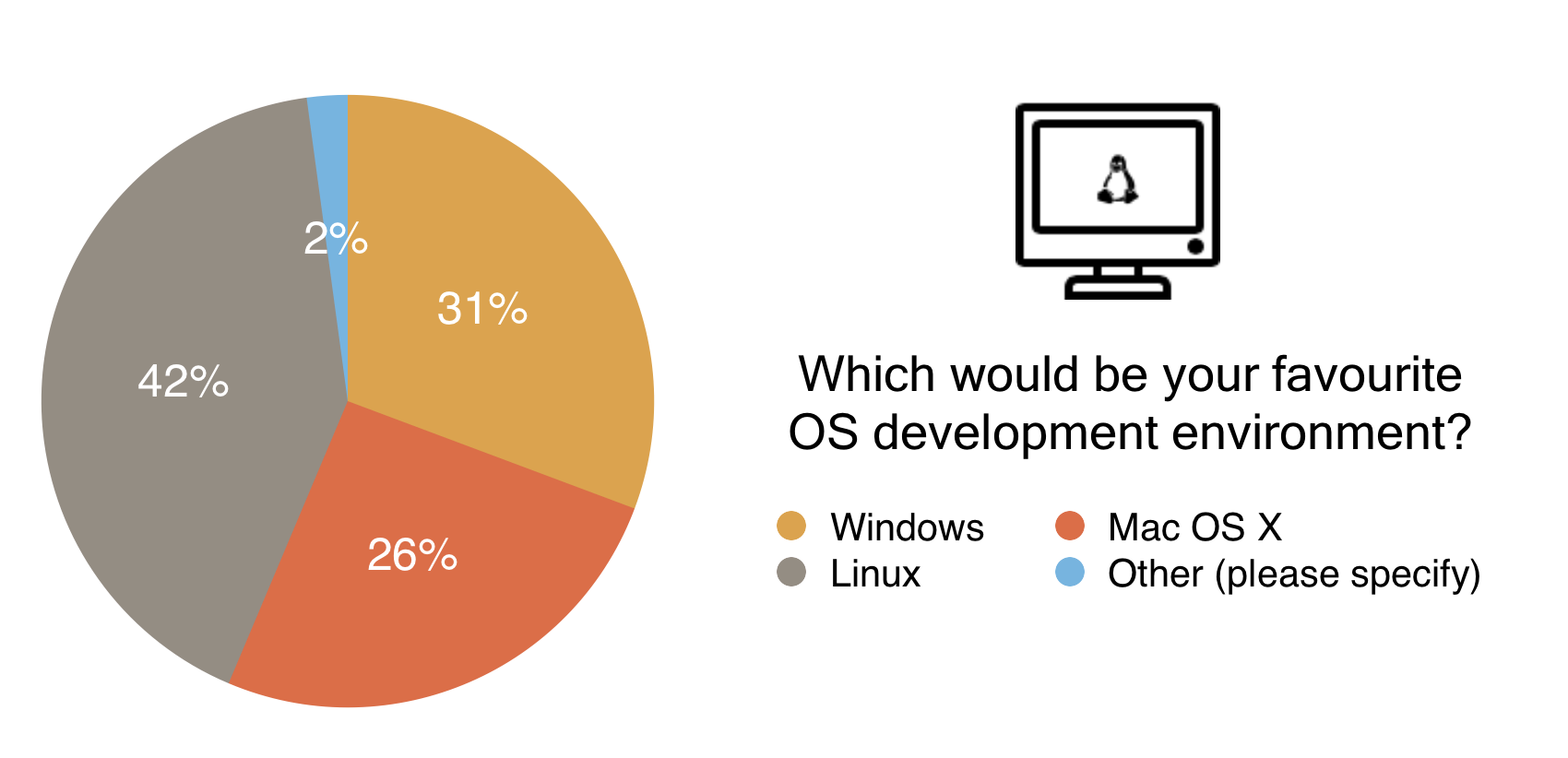
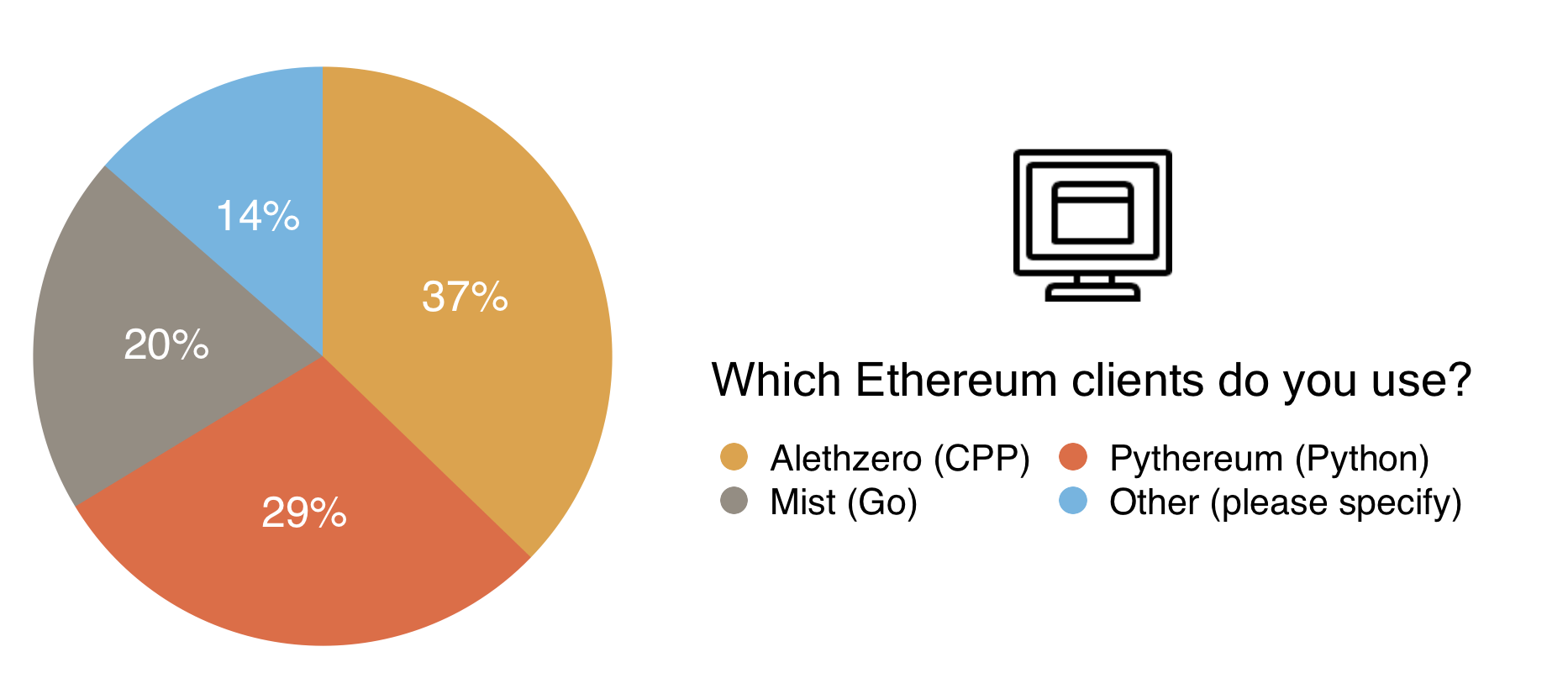
This chart shows a reasonably even spread, we’ve done our best to make the various clients available on different operating systems. You can find the Alethzero binaries here, and the Mist binaries here. These however become obsolete very quickly and may not connect to the test net as development continues, so if you considering using Ethereum before release, it’s well worth while checking the client building tutorials to get the most up to date versions of the clients.
With Mist (Go), Alethzero (C++), Pythereum (Python) Node-Ethereum (Node.js), and Ethereumj (Java), Ethereum already has a plethora of clients available. The Yellow Paper written by Gavin Wood is a great reference for the community to create its own clients, as seen with those still under development such as the Clojure and Objective C iterations.
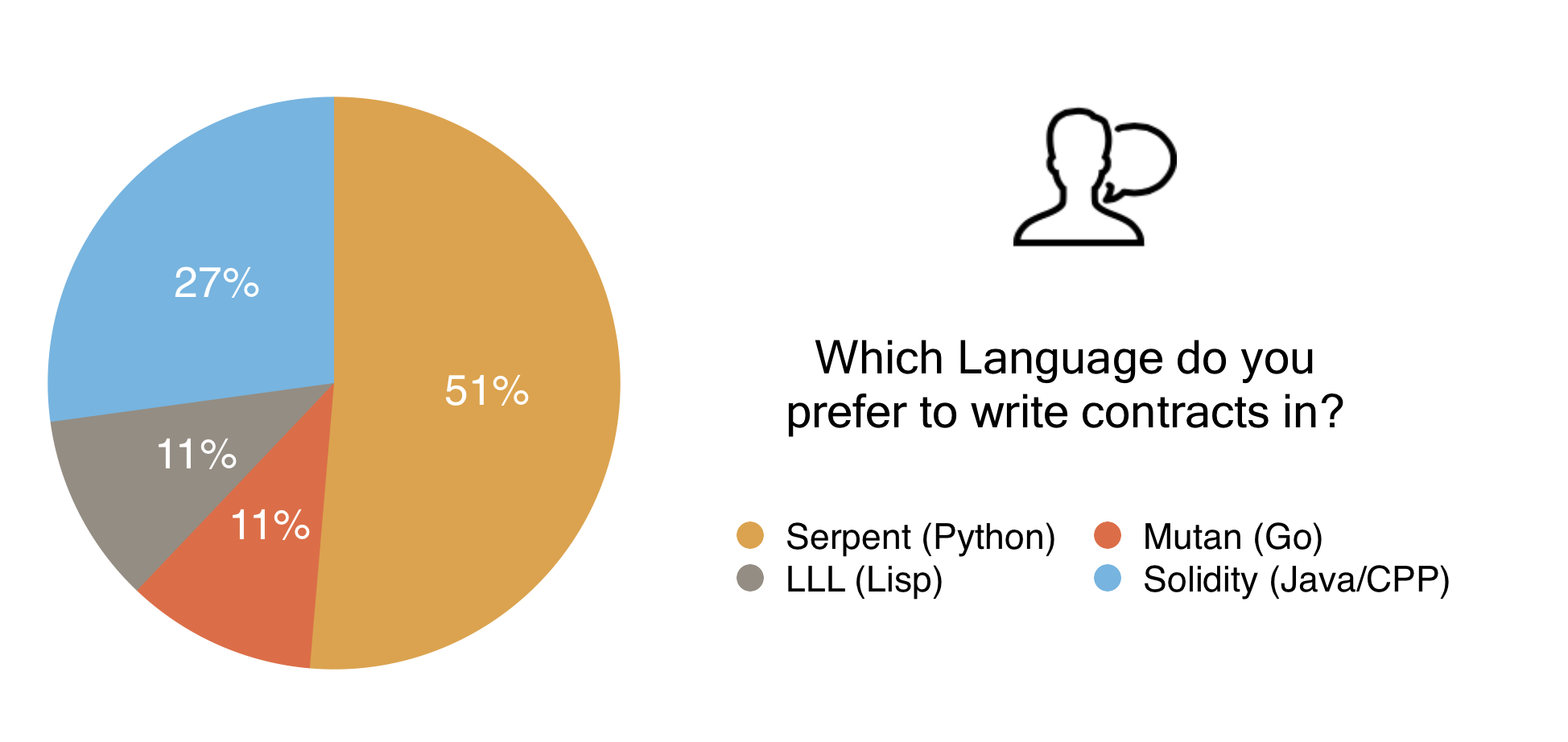
As Gavin Wood has mentioned in a previous blogpost, Mutan and LLL as smart contract languages will be mothballed. Serpent will be continued to be developed by Vitalik with his team, and Soldity will continue as the primary development language for Ethereum contracts. You can try Solidity in your browser, or watch the recent vision and roadmap presentation by Gavin Wood and Vitalik Buterin at ÐΞVcon-0.
Thanks to Alex Van de Sande for helping with the implementation of the survey and chart graphics. Icons retrieved from icons8. If anyone would like a copy of the raw survey results, feel free to email .
https://kinematec.de/wp-content/uploads/2015/01/ETH-WORLD-BETTER.png554924christianhttps://kinematec.de/wp-content/uploads/2019/10/kinematec_logo.pngchristian2015-01-09 19:36:022015-01-12 07:23:59Ethereum Community Survey
Superintendent Ben Lawsky hasn’t shied away from maintaining an open dialogue with the community.
While the early days of the web provide an intuitive roadmap for how the emergence of digital payment protocols and the ecosystem that surrounds them will evolve over time, there’s one defining difference between the evolving state of finance today and the Internet of the 80s: Regulations.
There’s a lot more at stake when transferring value versus information. It’s why finance is the most heavily regulated industry on the planet. It’s also why the internet-of-value has taken such a long time to materialize. The bar is just that much higher.
As these emerging technologies push us further into uncharted territory, navigating these regulatory waters has become a core component of our mission here at Ripple Labs. And as creators of an open source protocol, we’re committed to being transparent about that process. To provide insight on our perspective, we’re publishing our BitLicense comments (pdf), which we recently submitted to regulators.
Our position on regulations is straightforward. An effective regulatory framework opens the door to mainstream adoption. The goal is to provide necessary protections for end users without stifling innovation by burdening developers and small businesses. Instead, smart regulations can level the playing field, legitimize a burgeoning industry, and empower entrepreneurs.
But getting regulations right is an immense task. That’s why it’s pertinent that Ripple Labs works regularly with regulators, our numerous stakeholders, and the industry-at-large in helping to collectively shape the rules that will define the way forward.
BitLicense
It’s incredibly encouraging that the U.S. government appears up to the task with Superintendent Ben Lawsky of the New York State Department of Financial Services leading the way by maintaining an open dialogue and recently, drafting the first proposal of BitLicense, a set of rules that aim to bring clarity to how government officials and businesses deal with cryptocurrencies.
As the only U.S. regulator to step up to the plate—at both state and federal levels—Superintendent Lawsky should be commended for assuming this monumental responsibility. BitLicense elevates the industry as a whole, putting next generation firms in the same club as the big banks. Most of all, throughout Lawsky’s numerous interactions with the community—including his speech at Money20/20 in Las Vegas last month—it’s clear that New York’s first Superintendent of Financial Services not only comprehensively understands and respects the awesome potential of these new technologies but also what’s at stake.
Indeed, the implications of BitLicense will have far broader implications beyond the crypto-community, as Lawsky alluded to during his Vegas keynote, noting that his framework for Bitcoin regulations will eventually serve as a model for all regulated institutions. Along those lines, this isn’t merely about the future of Bitcoin or Ripple, it’s about the future of finance as a whole—one in which the lines between new technologies and the existing system continue to blur.
Again, for his fearless and influential leadership, Lawsky deserves to be commended. Even so, he could do more—especially if he and the rest of the state’s ruling body want New York to become a hub for technological innovation. Below is a summary of our comments and suggestions that we believe could help BitLicense reach its ultimate goals while still maintaining an environment that supports and fosters innovation and small businesses.
Reduce barriers of entry.New York should support developers who need the freedom to build. Costly compliance requirements create huge barriers of entry for small businesses. To accommodate innovation, we suggest a “registration regime” versus a “licensing regime” with a threshold for smaller firms, significantly reducing potential upfront costs and waiting around that often deters new businesses. This way, entrepreneurs can begin the regulatory process in good faith and start their business right away.
Create a level playing field. A key criticism of the initial BitLicense proposal is that it didn’t create a level playing field between cryptocurrencies and everyone else. There are arguments to be made why digital currencies should be held to a higher standard because of their unique properties, but if that’s the case, those arguments need to be explicitly mapped out, where each special feature is properly defined relative to existing rulesets. With the initial draft, it’s often unclear why increased controls are being implemented only for new technologies.
The rules regarding information security is one example, which requires third-party code verification. In this case, rather than opting for a more balanced approach, Lawsky went from 0-60 with baseline regulations. While it may be true that this new rule could very well be a “coming attraction for all banks,” emerging technologies shouldn’t have to serve as the canary in the coal mine and solely assume the cost of experimental rules. If a new rule is believed to be beneficial to the public’s interests, it should be applied to all relevant parties on day one, rather than arbitrarily to just the new kids on the block. Otherwise, BitLicense undermines a sense of fairness by appearing to favor established interests.
The overall scope is too broad.Such is the nature of emerging technologies with few past precedents—they can be difficult to properly define. But even under that context, the way BitLicense defines these new technologies is far too general and vague. If the purpose of regulations is to provide clarity, the proposal as it currently exists risks further muddying the waters by leaving ample room for subjective interpretation. The first step then is to provide a concise definition of the technology at hand. The approach we prefer is to highlight the technology’s fundamental distinctions. In the case of virtual currencies, this is the first time we’ve seen assets exist in a digital context (as opposed to liabilities).
Beyond reaching consensus on a proper definition, we believe that limiting the scope of these new regulations requires a more balanced and organic approach to how we assess risk. It’s logical to focus on the risks added by new technologies, but it’s equally as important to consider existing risks that innovation helps to mitigate. In that sense, BitLicense should not only temper negative characteristics, but also foster and expand positive ones. As it stands, the former is, at times, over the top, while the latter is often lacking.
The way forward
Overall, the development of BitLicense represents a huge step in the right direction, despite being imperfect as regulators and industry participants continue to work together toward a meaningful and mutually beneficial consensus. That governments are dedicating these resources toward legitimizing new businesses is a huge stamp of approval for technologies that only a few short years ago didn’t even exist.
At Ripple Labs, we’re deeply cognizant of our responsibility to our partners, our community, and the industry, and we take great pride in participating in this ongoing process, one we believe will have a huge impact on our ability to deliver these breakthrough technologies to people around the world.
That last part is key. Even if the U.S. will, at times, lead the way, the scope and reach of Ripple and other digital payment protocols in general transcends borders. As such, our regulatory work extends to a global scale. Last Friday, our team submitted a letter to the Australian Parliament regarding the regulation of digital currencies, which is available on their website for download. (We are submission #21.) We are also in the process of engaging with other foreign regulators.
As always—as an ongoing conversation and an evolving process—we are open to any and all feedback. We look forward to hearing from you.
Wir können Cookies anfordern, die auf Ihrem Gerät eingestellt werden. Wir verwenden Cookies, um uns mitzuteilen, wenn Sie unsere Websites besuchen, wie Sie mit uns interagieren, Ihre Nutzererfahrung verbessern und Ihre Beziehung zu unserer Website anpassen.
Klicken Sie auf die verschiedenen Kategorienüberschriften, um mehr zu erfahren. Sie können auch einige Ihrer Einstellungen ändern. Beachten Sie, dass das Blockieren einiger Arten von Cookies Auswirkungen auf Ihre Erfahrung auf unseren Websites und auf die Dienste haben kann, die wir anbieten können.
Notwendige Website Cookies
Diese Cookies sind unbedingt erforderlich, um Ihnen die auf unserer Webseite verfügbaren Dienste und Funktionen zur Verfügung zu stellen.
Da diese Cookies für die auf unserer Webseite verfügbaren Dienste und Funktionen unbedingt erforderlich sind, hat die Ablehnung Auswirkungen auf die Funktionsweise unserer Webseite. Sie können Cookies jederzeit blockieren oder löschen, indem Sie Ihre Browsereinstellungen ändern und das Blockieren aller Cookies auf dieser Webseite erzwingen. Sie werden jedoch immer aufgefordert, Cookies zu akzeptieren / abzulehnen, wenn Sie unsere Website erneut besuchen.
Wir respektieren es voll und ganz, wenn Sie Cookies ablehnen möchten. Um zu vermeiden, dass Sie immer wieder nach Cookies gefragt werden, erlauben Sie uns bitte, einen Cookie für Ihre Einstellungen zu speichern. Sie können sich jederzeit abmelden oder andere Cookies zulassen, um unsere Dienste vollumfänglich nutzen zu können. Wenn Sie Cookies ablehnen, werden alle gesetzten Cookies auf unserer Domain entfernt.
Wir stellen Ihnen eine Liste der von Ihrem Computer auf unserer Domain gespeicherten Cookies zur Verfügung. Aus Sicherheitsgründen können wie Ihnen keine Cookies anzeigen, die von anderen Domains gespeichert werden. Diese können Sie in den Sicherheitseinstellungen Ihres Browsers einsehen.
Andere externe Dienste
Wir nutzen auch verschiedene externe Dienste wie Google Webfonts, Google Maps und externe Videoanbieter. Da diese Anbieter möglicherweise personenbezogene Daten von Ihnen speichern, können Sie diese hier deaktivieren. Bitte beachten Sie, dass eine Deaktivierung dieser Cookies die Funktionalität und das Aussehen unserer Webseite erheblich beeinträchtigen kann. Die Änderungen werden nach einem Neuladen der Seite wirksam.
Google Webfont Einstellungen:
Google Maps Einstellungen:
Google reCaptcha Einstellungen:
Vimeo und YouTube Einstellungen:
Datenschutzrichtlinie
Sie können unsere Cookies und Datenschutzeinstellungen im Detail in unseren Datenschutzrichtlinie nachlesen.