Cryptocurrencies have now become commonplace in the online world. Although most of the media attention is focused on Bitcoin, Litecoin, Dogecoin, or other decentralised payment systems, the true revolution is happening at a much deeper level, one that does not involve only money. Bitcoin’s underlying technology – the “block chain” – has been adopted by many other applications with projects such as Maidsafe for distributed file storage, Twister or Bit-messaging for decentralised online communications, etc.
On 22 July 2014, a new cryptocurrency has become available on the market. After many months of preparation, Ethereum finally launched the pre-sale of its very own cryptocurrency – Ether – raising over 25.000 Bitcoin (approximatively $15.000.000) in less than two weeks. But what distinguishes Ethereum from other (more traditional) cryptocurrencies is that it provides a platform for the deployment of decentralised applications which have the potential to disrupt some of the most powerful organisations in advanced societies: those who instantiate financial and governmental institutions.
The role of institutions
An institution refers to any social structure in charge of governing the behaviour of individuals within a given community – such as law, money, religion, education, etc (Durkheim, 1985). This is generally achieved by means of formalised mechanisms of social order known as organisations – such as the government, the bank, the church, and so forth.
Institutions are needed to coordinate actions and stabilise expectations amongst a disparate set of individuals – two objectives that could, historically, only be achieved through hierarchical organisations and centralised forms of control.
The former (coordination) is achieved when there are efficient and effective interactions amongst a non-coordinated group of individuals – just like banks coordinate the savings and investments of multiple individuals and organisations.
The latter (trust) requires an organisation to be both accountable and sustainable over time. For instance, we expect banks to be responsible, and to operate with relatively predictable patterns over a long period of time.
The problem with institutions is not their function, but rather the centralised structure of the organisations that subtend them. Centralisation is costly because it relies on the aggregation of information for decision-making, which reduces the ability of such organisations to react promptly to their changing environment. Moreover, centralisation encourages the accumulation of resources and power in the hands of a few individuals, at the expense of less privileged groups.
Can the core functions of institutions – coordination and trust – be achieved by means of decentralised applications, thus avoiding the costs of centralised control?
Bitcoin – disrupting the financial institution
Let us take a look at how the financial system is affected by modern decentralised technologies. There has been a long history of pre-digital complementary currencies, such as the Bavarian “wära” and other Gesellian currencies, and multiple experiments were made during the 1990s and the early 2000s with new digital currencies, such as E-gold and the Liberty Dollar. Most of them failed because of scams, instability and scalability problems, some were even involved with massive money laundering regimes and eventually were shut down and/or seized.
Learning from previous failures, Bitcoin, as a decentralised cryptocurrency, represents a true discontinuity from the rest.
Created by the fictional character Satoshi Nakamoto, the Bitcoin network relies on basic cryptographic tools (such as public/private key encryption and digital signatures) to produce and maintain a decentralised public ledger (or “blockchain”) recording all transactions that have been made (and will be made) on the network. The validity and legitimacy of these transactions is verified through the process of “mining” – a process that relies on full transparency and peer-to-peer collaboration to overcome the coordination problems that are typical of decentralised networks (Nakamoto, 2008).
Contrarily to other virtual currencies, Bitcoin overcame several scams and attacks. In spite of the various incidents of theft due to the so-called transaction malleability (allowing for the unique ID of a Bitcoin transaction to be modified before it is confirmed on the Bitcoin network) and the recent BGP hack (exploiting the Internet Border Gateway Protocol to redirect mining traffic to a malicious server), Bitcoin is still strong and alive. Indeed, most of these attacks are due not to a flaw in the Bitcoin protocol, but rather to a lack of understanding and poor security measures taken by Bitcoin users or exchanges.
Facing dramatic price swings and hostile regulatory environments (De Filippi, 2014a), the Bitcoin network coordinates today over tens of thousands of transactions per day, in a relatively efficient manner. The network reflects within its own system the qualities of coordination and trust: two features which are key to the success of many financial organisations and monetary systems.
Yet, Bitcoin constitutes a major change in comparison with previous payment systems to the extent that it enables true independence from centralised forms of control. By creating a trustless system (where strangers can interact without having to trust each other), Bitcoin shifted the focus of trust away from the financial institution, towards the technology underlying the network. In this way, Bitcoin has proven that it is possible to implement a working decentralised currency system that remains independent from governments and corporations.
But Bitcoin’s real innovation is not the currency itself. The Bitcoin blockchain can extend beyond the monetary realm, to support all forms of social, legal and political transactions (De Filippi, 2014b).
Ethereum – disrupting social and political institutions
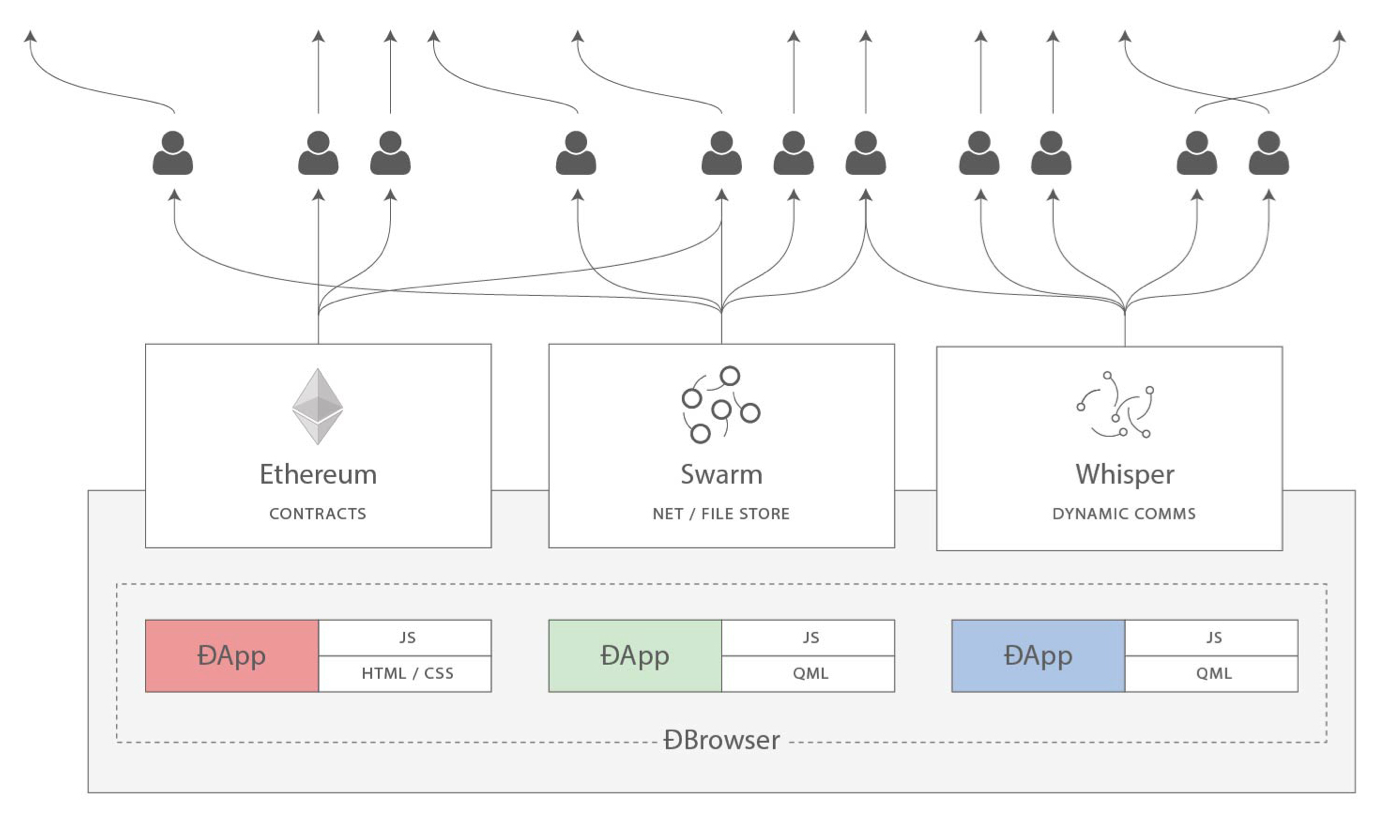
Thus far the most powerful example of blockchain-based application is Ethereum, an innovative platform that implements a turing complete scripting language (i.e., one that can solve any possible computational problem) on top of a decentralised cryptocurrency.
Ethereum builds upon the technology of Bitcoin to manage and coordinate different kinds of transactions in a trustless and distributed fashion (Buterin, 2014). While Bitcoin is limited to financial transactions, Ethereum can cover different types of transactions, provided that these can be ‘encoded’ into the blockchain. Financial instruments – such as insurance contracts or derivatives – can be translated into code so as to be understood and automatically enforced by the platform. Physical assets – such as smart phones or smart cars – can be linked to one or more cryptographic tokens that will determine both who owns them and who is entitled to use them. More generally, and perhaps most importantly, Ethereum can be used to regulate social interactions between individuals – such as an employer and its employees, or a licensor and its licensees – through a series of electronic agreements (i.e., smart-contracts) whose provisions can be automatically enforced by the underlying code of the platform; the mechanism by which the contract is defined (i.e., the code) is the same mechanism through which the contract is enforced.
As a result, Ethereum eliminates the need for trust between parties as well as the need for a centralised entity coordinating these parties. People can thus coordinate themselves, in a trustless (since the trust has been shifted onto the technology) and decentralised manner, without having to rely on the services of any third party institution – be it a corporate body or public institution.
Hence, what Bitcoin did to the financial system, Ethereum could do to the political system as a whole. In other words, if Bitcoin was designed as a decentralised alternative to counteract the corruption and inefficiency of the monetary system, Ethereum constitutes a decentralised alternative to the notion of the organisation per se.
Through its decentralised application platform, Ethereum eliminates the need for people to rely on centralised authorities and traditional, top-down governance models, to experiment instead with novel forms of distributed governance where decision-making occurs at the edges of the network. In this sense, Ethereum could contribute to supplanting centralised and hierarchical organisations with more decentralised (autonomous) organisations relying on contract-based coordination.
Today, Ethereum already appears to be a promising technology, at least considering the hype that has built up around it. Following the first two weeks of pre-sale, over 54.000.000 Ether have already been sold (worth almost $16.000.000 as of 1 August 2014). But the most interesting part has yet to come, as Ethereum’s official release will only happen during the last quarter of 2014. We are just witnessing today the emergence of new opportunities for individual emancipation and self-coordination.
Ethereum facilitates a new form of distributed private ordering between a decentralised network of peers, which significantly differs from the traditional regulatory mechanisms employed by centralised organisations and public authorities. In the future, we might be able to build decentralised organisations with distributed models of governance, independent legal systems, or perhaps even autonomously governed communities that would compete with both governments and corporations.