One of the criticisms that many people have made about the current direction of the cryptocurrency space is the increasing amount of fragmentation that we are seeing. What was earlier perhaps a more tightly bound community centered around developing the common infrastructure of Bitcoin is now increasingly a collection of “silos”, discrete projects all working on their own separate things. There are a number of developers and researchers who are either working for Ethereum or working on ideas as volunteers and happen to spend lots of time interacting with the Ethereum community, and this set of people has coalesced into a group dedicated to building out our particular vision. Another quasi-decentralized collective, Bitshares, has set their hearts on their own vision, combining their particular combination of DPOS, market-pegged assets and vision of blockchain as decentralized autonomous corporation as a way of reaching their political goals of free-market libertarianism and a contract free society. Blockstream, the company behind “sidechains”, has likewise attracted their own group of people and their own set of visions and agendas – and likewise for Truthcoin, Maidsafe, NXT, and many others.
One argument, often raised by Bitcoin maximalists and sidechains proponents, is that this fragmentation is harmful to the cryptocurrency ecosystem – instead of all going our own separate ways and competing for users, we should all be working together and cooperating under Bitcoin’s common banner. As Fabian Brian Crane summarizes:
One recent event that has further inflamed the discussion is the publication of the sidechains proposal. The idea of sidechains is to allow the trustless innovation of altcoins while offering them the same monetary base, liquidity and mining power of the Bitcoin network.
For the proponents, this represents a crucial effort to rally the cryptocurrency ecosystem behind its most successful project and to build on the infrastructure and ecosystem already in place, instead of dispersing efforts in a hundred different directions.
Even to those who disagree with Bitcoin maximalism, this seems like a rather reasonable point, and even if the cryptocurrency community should not all stand together under the banner of “Bitcoin” one may argue that we need to all stand together somehow, working to build a more unified ecosystem. If Bitcoin is not powerful enough to be a viable backbone for life, the crypto universe and everything, then why not build a better and more scalable decentralized computer instead and build everything on that? Hypercubes certainly seem powerful enough to be worth being a maximalist over, if you’re the sort of person to whom one-X-to-rule-them-all proposals are intuitively appealing, and the members of Bitshares, Blockstream and other “silos” are often quite eager to believe the same thing about their own particular solutions, whether they are based on merged-mining, DPOS plus BitAssets or whatever else.
So why not? If there truly is one consensus mechanism that is best, why should we not have a large merger between the various projects, come up with the best kind of decentralized computer to push forward as a basis for the crypto-economy, and move forward together under one unified system? In some respects, this seems noble; “fragmentation” certainly has undesirable properties, and it is natural to see “working together” as a good thing. In reality, however, while more cooperation is certainly useful, and this blog post will later describe how and why, desires for extreme consolidation or winner-take-all are to a large degree exactly wrong – not only is fragmentation not all that bad, but rather it’s inevitable, and arguably the only way that this space can reasonably prosper.
Agree to Disagree
Why has fragmentation been happening, and why should we continue to let it happen? To the first question, and also simultaneously to the second, the answer is simple: we fragment because we disagree. Particularly, consider some of the following claims, all of which I believe in, but which are in many cases a substantial departure from the philosophies of many other people and projects:
- I do not think that weak subjectivity is all that much of a problem. However, mugh higher degrees of subjectivity and intrinsic reliance on extra-protocol social consensus I am still not comfortable with.
- I consider Bitcoin’s $ 600 million/year wasted electricity on proof of work to be an utter environmental and economic tragedy.
- I believe ASICs are a serious problem, and that as a result of them Bitcoin has become qualitatively less secure over the past two years.
- I consider Bitcoin (or any other fixed-supply currency) to be too incorrigibly volatile to ever be a stable unit of account, and believe that the best route to cryptocurrency price stability is by experimenting with intelligently designed flexible monetary policies (ie. NOT “the market” or “the Bitcoin central bank“). However, I am not interested in bringing cryptocurrency monetary policy under any kind of centralized control.
- I have a substantially more anti-institutional/libertarian/anarchistic mindset than some people, but substantially less so than others (and am incidentally not an Austrian economist). In general, I believe there is value to both sides of the fence, and believe strongly in being diplomatic and working together to make the world a better place.
- I am not in favor of there being one-currency-to-rule-them-all, in the crypto-economy or anywhere.
- I think token sales are an awesome tool for decentralized protocol monetization, and that everyone attacking the concept outright is doing a disservice to society by threatening to take away a beautiful thing. However, I do agree that the model as implemented by us and other groups so far has its flaws and we should be actively experimenting with different models that try to align incentives better
- I believe futarchy is promising enough to be worth trying, particularly in a blockchain governance context.
- I consider economics and game theory to be a key part of cryptoeconomic protocol analysis, and consider the primary academic deficit of the cryptocurrency community to be not ignorance of advanced computer science, but rather economics and philosophy. We should reach out to http://lesswrong.com/ more.
- I see one of the primary reasons why people will adopt decentralized technologies (blockchains, whisper, DHTs) in practice to be the simple fact that software developers are lazy, and do not wish to deal with the complexities of maintaining a centralized website.
- I consider the blockchain-as-decentralized-autonomous-corporation metaphor to be useful, but limited. Particularly, I believe that we as cryptocurrency developers should be taking advantage of this perhaps brief period in which cryptocurrency is still an idealist-controlled industry to design institutions that maximize utilitarian social welfare metrics, not profit (no, they are not equivalent, primarily because of these).
There are probably very few people who agree with me on every single one of the items above. And it is not just myself that has my own peculiar opinions. As another example, consider the fact that the CTO of OpenTransactions, Chris Odom, says things like this:
What is needed is to replace trusted entities with systems of cryptographic proof. Any entity that you see in the Bitcoin community that you have to trust is going to go away, it’s going to cease to exist … Satoshi’s dream was to eliminate [trusted] entities entirely, either eliminate the risk entirely or distribute the risk in a way that it’s practically eliminated.
Meanwile, certain others feel the need to say things like this:
Put differently, commercially viable reduced-trust networks do not need to protect the world from platform operators. They will need to protect platform operators from the world for the benefit of the platform’s users.
Of course, if you see the primary benefit of cryptocurrency as being regulation avoidance then that second quote also makes sense, but in a way completely different from the way its original author intended – but that once again only serves to show just how differently people think. Some people see cryptocurrency as a capitalist revolution, others see it as an egalitarian revolution, and others see everything in between. Some see human consensus as a very fragile and corruptible thing and cryptocurrency as a beacon of light that can replace it with hard math; others see cryptocurrency consensus as being only an extension of human consensus, made more efficient with technology. Some consider the best way to achieve cryptoassets with dollar parity to be dual-coin financial derivative schemes; others see the simpler approach as being to use blockchains to represent claims on real-world assets instead (and still others think that Bitcoin will eventually be more stable than the dollar all on its own). Some think that scalability is best done by “scaling up“; others believe the ultimately superior option is “scaling out“.
Of course, many of these issues are inherently political, and some involve public goods; in those cases, live and let live is not always a viable solution. If a particular platform enables negative externalities, or threatens to push society into a suboptimal equilibrium, then you cannot “opt out” simply by using your platform instead. There, some kind of network-effect-driven or even in extreme cases 51%-attack-driven censure may be necessary. In some cases, the differences are related to private goods, and are primarily simply a matter of empirical beliefs. If I believe that SchellingDollar is the best scheme for price stability, and others prefer Seignorage Shares or NuBits then after a few years or decades one model will prove to work better, replace its competition, and that will be that.
In other cases, however, the differences will be resolved in a different way: it will turn out that the properties of some systems are better suited for some applications, and other systems better suited for other applications, and everything will naturally specialize into those use cases where it works best. As a number of commentators have pointed out, for decentralized consensus applications in the mainstream financial world, banks will likely not be willing to accept a network managed by anonymous nodes; in this case, something like Ripple will be more useful. But for Silk Road 4.0, the exact opposite approach is the only way to go – and for everything in between it’s a cost-benefit analysis all the way. If users want networks specialized to performing specific functions highly efficiently, then networks will exist for that, and if users want a general purpose network with a high network effect between on-chain applications then that will exist as well. As David Johnston points out, blockchains are like programming languages: they each have their own particular properties, and few developers religiously adhere to one language exclusively – rather, we use each one in the specific cases for which it is best suited.
Room for Cooperation
However, as was mentioned earlier, this does not mean that we should simply go our own way and try to ignore – or worse, actively sabotage, each other. Even if all of our projects are necessarily specializing toward different goals, there is nevertheless a substantial opportunity for much less duplication of effort, and more cooperation. This is true on multiple levels. First, let us look at a model of the cryptocurrency ecosystem – or, perhaps, a vision of what it might look like in 1-5 years time:
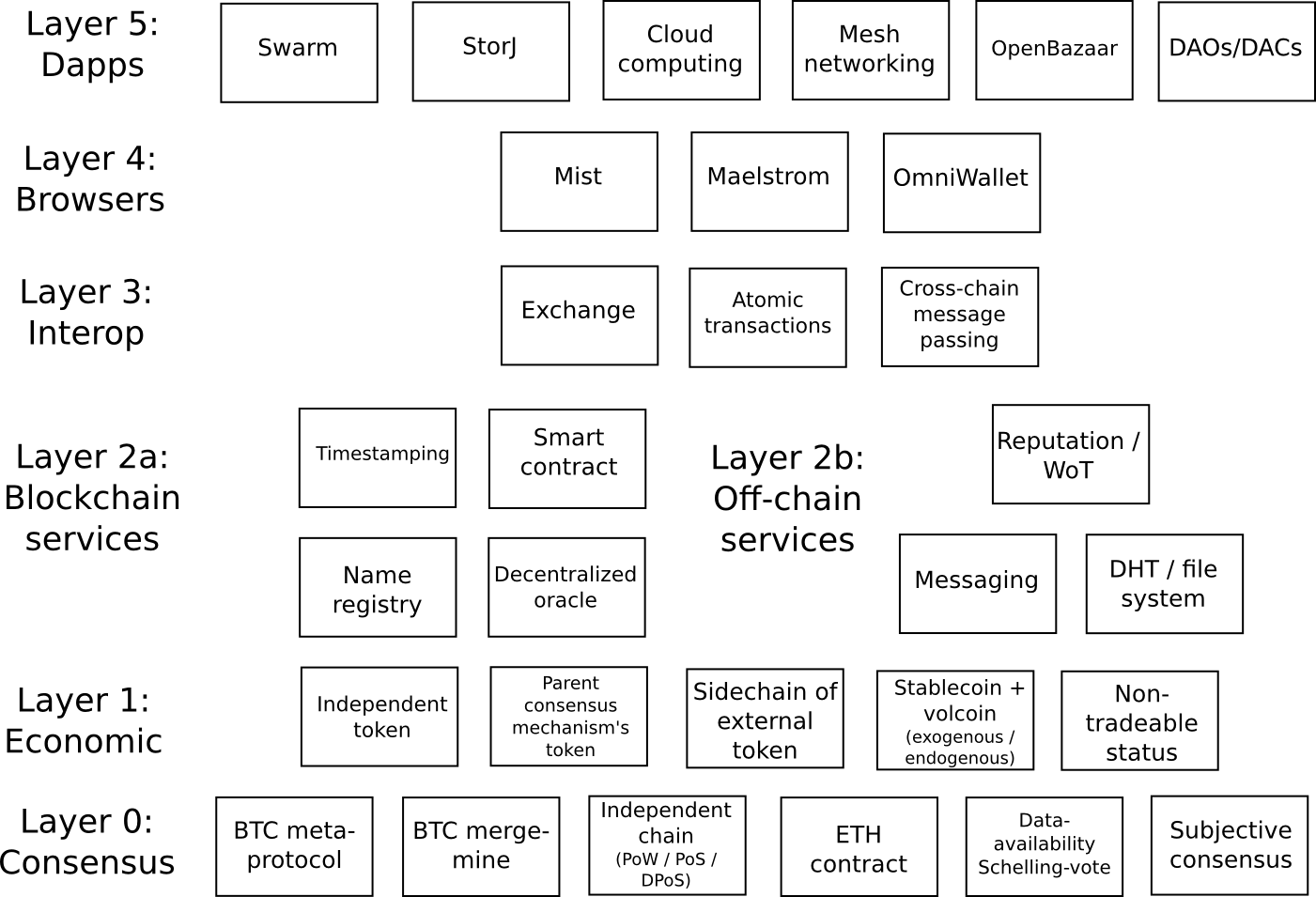
Ethereum has its own presence on pretty much every level:
- Consensus: Ethereum blockchain, data-availablility Schelling-vote (maybe for Ethereum 2.0)
- Economics: ether, an independent token, as well as research into stablecoin proposals
- Blockchain services: name registry
- Off-chain services: Whisper (messaging), web of trust (in progress)
- Interop: BTC-to-ether bridge (in progress)
- Browsers: Mist
Now, consider a few other projects that are trying to build holistic ecosystems of some kind. Bitshares has at the least:
- Consensus: DPOS
- Economics: BTSX and BitAssets
- Blockchain services: BTS decentralized exchange
- Browsers: Bitshares client (though not quite a browser in the same concept)
Maidsafe has:
- Consensus: SAFE network
- Economics: Safecoin
- Off-chain services: Distributed hash table, Maidsafe Drive
BitTorrent has announced their plans for Maelstrom, a project intended to serve a rather similar function to Mist, albeit showcasing their own (not blockchain-based) technology. Cryptocurrency projects generally all build a blockchain, a currency and a client of their own, although forking a single client is common for the less innovative cases. Name registration and identity management systems are now a dime a dozen. And, of course, just about every project realizes that it has a need for some kind of reputation and web of trust.
Now, let us paint a picture of an alternative world. Instead of having a collection of cleanly disjoint vertically integrated ecosystems, with each one building its own components for everything, imagine a world where Mist could be used to access Ethereum, Bitshares, Maidsafe or any other major decentralized infrastructure network, with new decentralized networks being installable much like the plugins for Flash and Java inside of Chrome and Firefox. Imagine that the reputation data in the web of trust for Ethereum could be reused in other projects as well. Imagine StorJ running inside of Maelstrom as a dapp, using Maidsafe for a file storage backend, and using the Ethereum blockchain to maintain the contracts that incentivize continued storage and downloading. Imagine identities being automatically transferrable across any crypto-networks, as long as they use the same underlying cryptographic algorithms (eg. ECDSA + SHA3).
The key insight here is this: although some of the layers in the ecosystem are inextricably linked – for example, a single dapp will often correspond to a single specific service on the Ethereum blockchain – in many cases the layers can easily be designed to be much more modular, allowing each product on each layer to compete separately on its own merits. Browsers are perhaps the most separable component; most reasonably holistic lower level blockchain service sets have similar needs in terms of what applications can run on them, and so it makes sense for each browser to support each platform. Off-chain services are also a target for abstraction; any decentralized application, regardless of what blockchain technology it uses, should be free to use Whisper, Swarm, IPFS or any other service that developers come up with. On-chain services, like data provision, can theoretically be built so as to interact with multiple chains.
Additionally, there are plenty of opportunities to collaborate on fundamental research and development. Discussion on proof of work, proof of stake, stable currency systems and scalability, as well as other hard problems of cryptoeconomics can easily be substantially more open, so that the various projects can benefit from and be more aware of each other’s developments. Basic algorithms and best practices related to networking layers, cryptographic algorithm implementations and other low-level components can, and should, be shared. Interoperability technologies should be developed to facilitate easy exchange and interaction between services and decentralized entities on one platform and another. The Cryptocurrency Research Group is one initiative that we plan to initially support, with the hope that it will grow to flourish independently of ourselves, with the goal of promoting this kind of cooperation. Other formal and informal institutions can doubtlessly help support the process.
Hopefully, in the future we will see many more projects existing in a much more modular fashion, living on only one or two layers of the cryptocurrency ecosystem and providing a common interface allowing any mechanism on any other layer to work with them. If the cryptocurrency space goes far enough, then even Firefox and Chrome may end up adapting themselves to process decentralized application protocols as well. A journey toward such an ecosystem is not something that needs to be rushed immediately; at this point, we have quite little idea of what kinds of blockchain-driven services people will be using in the first place, making it hard to determine exactly what kind of interoperability would actually be useful. However, things slowly but surely are taking their first few steps in that direction; Eris’s Decerver, their own “browser” into the decentralized world, supports access to Bitcoin, Ethereum, their own Thelonious blockchains as well as an IPFS content hosting network.
There is room for many projects that are currently in the crypto 2.0 space to succeed, and so having a winner-take-all mentality at this point is completely unnecessary and harmful. All that we need to do right now to set off the journey on a better road is to live with the assumption that we are all building our own platforms, tuned to our own particular set of preferences and parameters, but at the end of the day a plurality of networks will succeed and we will need to live with that reality, so might as well start preparing for it now.
Happy new year, and looking forward to an exciting 2015 007 Anno Satoshii.
The post On Silos appeared first on ethereum blog.