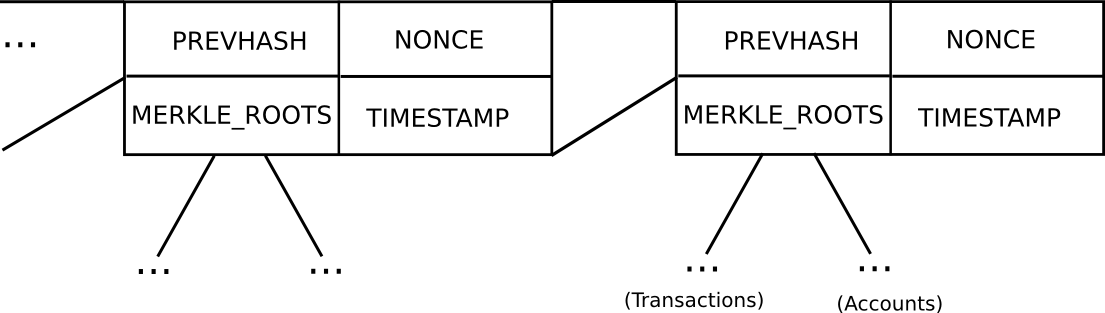
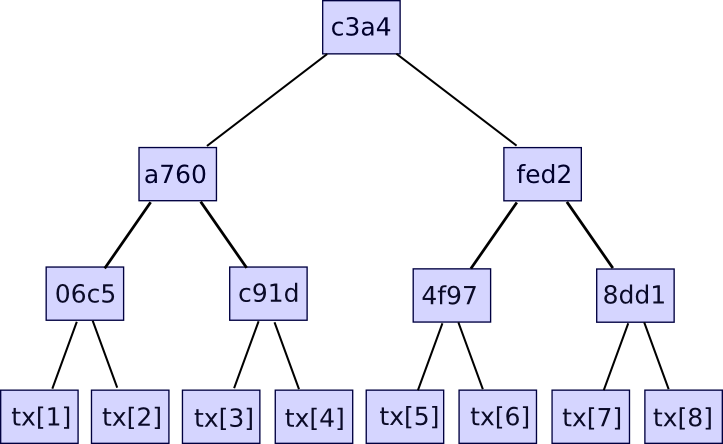
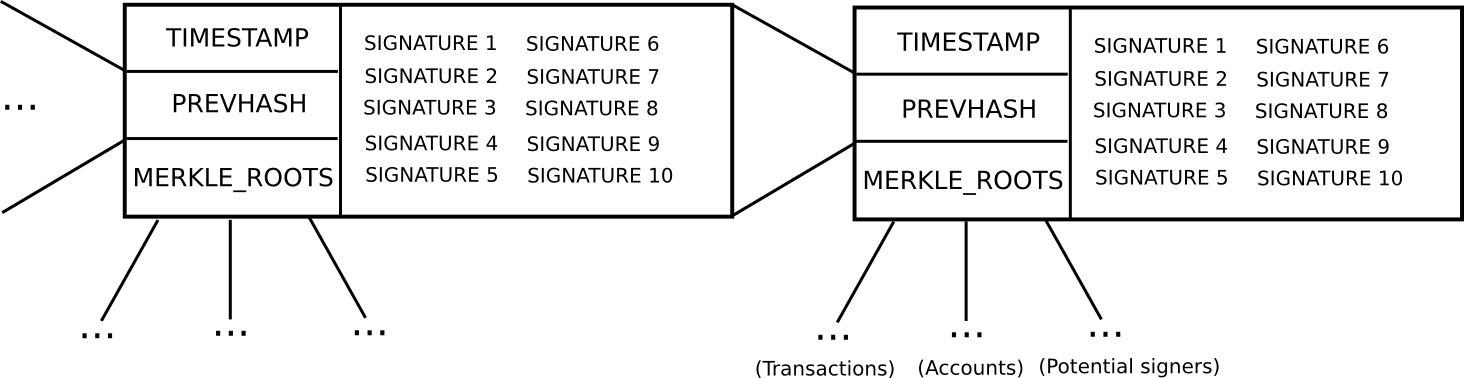
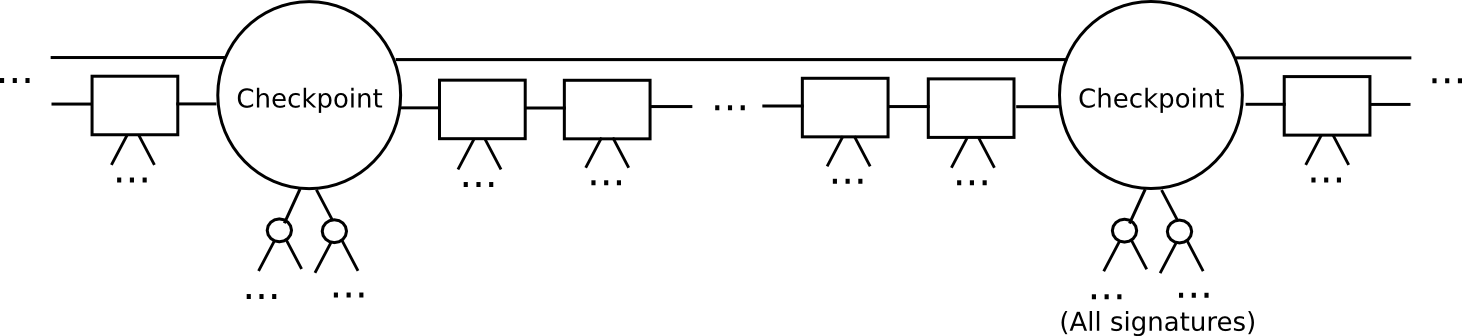
Consumers are demanding faster payments in the UK. Photo: Flickr
This is part 1 of our 2-part interview series with Jeremy Light on the future of payments.
Real-time payments is the hottest topic in Europe if not globally, says Jeremy Light, a managing director at Accenture and payments industry expert.
When you think of influential authorities in the payments space, Jeremy instantly comes to mind. As head of Accenture Payment Services in Europe, Africa, and Latin America, Jeremy focuses on strategy, systems integration, and outsourcing.
A prolific thought leader, Jeremy regularly produces groundbreaking industry publications—such as his report, “Digital Payment Transformation”—and also maintains a blog. He was named Accenture’s Inventor of the Year 2015 after being awarded a mobile payments patent in 2014 along with his colleagues.
We recently caught up with Jeremy to get his take on the future of payments.
Ripple Labs: Everyone seems to be talking about real-time payments these days.
Jeremy Light: I would say probably the hottest topic in Europe if not globally is real-time payments. The Euro Banking Association (EBA) is focused on it. So is the European Central Bank (ECB). At the end of last year, the ECB issued a challenge to the banking industry in Europe—for them to develop a cohesive vision for building real-time payments infrastructure. They didn’t want to see disparate systems being set up around Europe that didn’t work together.
The EBA, which also performs a clearing function, set up a forum earlier this year across Europe to spark a discussion on real-time payments. But even without the extra nudge, we’re seeing progress in quite a few countries around the world, where banks are investigating how they can set up a real-time clearing system.
Last year, Finland issued a request for information (RFI), which described the national payment system there as quickly becoming obsolete. The Netherlands just announced that they’re going to set up real-time payments. Dutch banks plan to have real-time solutions set up by 2019. The EBA itself has just issued a blueprint for a pan-European instant payment infrastructure to be implemented from 2016 to 2018.
RL: So real-time is clearly on everyone’s minds. What are the biggest challenges moving forward? What are the major roadblocks?
Jeremy: Well, one major challenge is getting banks not only to adopt new technology and infrastructure, but also offer these products to their customers. Even now, there are banks around Europe that will say that their customers aren’t asking for real-time payments, that same day or next day payments is good enough.
RL: It kind of sounds like how Internet providers here in the US will say that their customers don’t want faster broadband speeds.
Jeremy: Right. Consider the UK, where we’ve had the Faster Payments System since 2008, which, by the way, is now growing very strongly. Despite having the capabilities all these years, banks haven’t really promoted or marketed real-time payments. That’s not necessarily the fault of the banks either. A lot of small businesses, until recently, have been more than content with same day payments. But I would say that in the past 18 months, there’s been a big shift in attitude. We can’t pinpoint exactly why, but customers are now demanding real-time payments.
As a result, those banks that can’t offer guaranteed real-time payments 24/7/365, they’re starting to notice that their customers are complaining because they see this service being offered by competitors. They see others doing it, that it’s possible and that it’s happening. So there’s definitely been a wave of change regarding expectations in the last year or so.
Here in the UK, we have a lot of upstart banks, called challenger banks, encouraged by the government’s drive to open up competition in the banking industry. These new banks realize that they have to offer a real-time payments proposition because if they don’t, they’ll be at a huge disadvantage.
RL: Which makes sense. Everything else in our world today is on demand. The Internet has wired us for instant gratification.
Exactly. We suspect that this shift in expectations is part of the rise of the digital age. People’s lives are governed by their smartphones and they experiences they get with Google, Amazon, and Apple, where everything is immediate and instantaneous. It’s pushing banks to change their stance.
Consider a scenario if a bank in Europe wanted to offer mobile payments because their customers are demanding it. If i send you a payment by mobile and you get a message—Jeremy just sent you $ 15.
But then you look at your bank account and you don’t see the money, it’s a problem. It becomes a source of uncertainty and anxiety. You don’t know when your money will arrive or even if it will arrive. And banks get that. They realize that they can’t offer mobile payments unless it’s in real-time and it’s a sea change that’s occurring across Europe.
So most banks, most countries are realizing that they need to implement these systems because if you think about it, it’s the natural progression. It’s evolution. Like you said, everyone is used to real-time in every other aspect of their lives. It just makes sense. When people send you an email, they want an instant response. If I ask you a question, I want an answer. I don’t want it tomorrow. I want it immediately.
RL: Given all of that, where do you think distributed ledgers fit into the equation?
It’s an interesting question. The distributed consensus ledger technology that Ripple offers and that blockchain technologies offer is coming along at just the right time when banks are looking at real-time payments. So there’s an immense amount of interest in what these innovations have to offer.
The caveat of course, is that these technologies still need to mature, particularly if we’re talking about the blockchain. If you look at Bitcoin, the maximum transactions right now is maybe around 3 or 4 per second. Then you look at Visa, which can process around 45,000 transactions per second. Bitcoin also isn’t technically real-time since it takes at least ten minutes to confirm a transaction. That isn’t to say these issues can’t be addressed, but right now, the technology hasn’t advanced yet and in terms of businesses offering real solutions, I haven’t seen any credible candidates. I don’t see it as this incredible technology that offers a solution for the immediate future. On the other hand, Ripple confirms transactions in seconds, which, I expect, is what banks are looking for.
RL: You make a great point about Visa. A lot of people will say, look, we can already do real-time with a centralized ledger and so they don’t understand the appeal of a distributed system.
Jeremy: That’s a key question. Why distributed ledgers? For one, a distributed solution enforces integrity and commonality versus one central ledger that everyone can access.
At the same time, central clearing and settlement is very efficient. Most clearing and settlement systems today can handle very high volume and they rarely have issues. Apart from very occasional hiccups, such as in the UK wire system last year, we haven’t really had issues regarding resilience.
Still, having these central, proprietary systems adds a lot of complexity and cost on the bank side. There’s a lot of different systems and these systems don’t interoperate with each other. This adds to operational issues and operational processes. So if we consider long term costs, a distributed ledger could conceivably be a better, more efficient solution, and there’s certainly the potential to do that. That’s why these technologies are so interesting for banks.
We’re still in the discovery phase around cryptotechnologies, distributed consensus ledgers. What will be intriguing to banks and financial institutions is to figure out how they can leverage the advantages of these innovations.
RL: Maybe this is an obvious questions, but what are the immediate benefits of real-time payments, given that customers are now demanding it as a service?
From a consumer point of view, there are two main advantages. The first is that you have real-time availability of funds. If I give my daughter a pound coin, she can immediately go and buy an ice cream, rather than in a few hours or the next morning. When you have real-time availability of funds, you’re much more flexible with what you can do.
The second advantage is the ability to provide a seamless customer experience. We’ve noticed that in the UK, if a bank has delays of even just 10 minutes, customers service call volumes go up significantly because someone was sent money, but when they go to the ATM, it hasn’t arrived yet.
People enjoy a sense of certainty. They like knowing that a job is done so they can forget about it. Today, because PayPal is connected to the Faster Payments System, you can move money between your bank account and PayPal account in real-time. The same goes for people who have accounts at different institutions, you can send money from one bank to another instantaneously. If you initiate a transaction and you see that it’s left one account and it hasn’t arrived in another, it’s painful.
That’s the customer proposition. It’s instant gratification, essentially cashless cash. If you give cash to someone, a $ 20 bill, that’s it. The transaction is done and you can move on. That’s the beauty of real-time payments.
And this is exactly the trend we are seeing. In the UK, we predict volumes on the Faster Payments System to double or triple in the next few years, and they are already at over a billion payments per year.