Presented by Stephan Tual, CCO. Companion Document: https://medium.com/@ethereumproject/4790bf5f7743 Ethereum is a platform that makes it possible for any de… Categories : Kryptowährungen. Bookmark the …
ethereum – Google Blogsuche
Proof of stake continues to be one of the most controversial discussions in the cryptocurrency space. Although the idea has many undeniable benefits, including efficiency, a larger security margin and future-proof immunity to hardware centralization concerns, proof of stake algorithms tend to be substantially more complex than proof of work-based alternatives, and there is a large amount of skepticism that proof of stake can work at all, particularly with regard to the supposedly fundamental “nothing at stake” problem. As it turns out, however, the problems are solvable, and one can make a rigorous argument that proof of stake, with all its benefits, can be made to be successful – but at a moderate cost. The purpose of this post will be to explain exactly what this cost is, and how its impact can be minimized.
Economic Sets and Nothing at Stake
First, an introduction. The purpose of a consensus algorithm, in general, is to allow for the secure updating of a state according to some specific state transition rules, where the right to perform the state transitions is distributed among some economic set. An economic set is a set of users which can be given the right to collectively perform transitions via some algorithm, and the important property that the economic set used for consensus needs to have is that it must be securely decentralized – meaning that no single actor, or colluding set of actors, can take up the majority of the set, even if the actor has a fairly large amount of capital and financial incentive. So far, we know of three securely decentralized economic sets, and each economic set corresponds to a set of consensus algorithms:
- Owners of computing power: standard proof of work, or TaPoW. Note that this comes in specialized hardware, and (hopefully) general-purpose hardware variants.
- Stakeholders: all of the many variants of proof of stake
- A user’s social network: Ripple/Stellar-style consensus
Note that there have been some recent attempts to develop consensus algorithms based on traditional Byzantine fault tolerance theory; however, all such approaches are based on an M-of-N security model, and the concept of “Byzantine fault tolerance” by itself still leaves open the question of which set the N should be sampled from. In most cases, the set used is stakeholders, so we will treat such neo-BFT paradigms are simply being clever subcategories of “proof of stake”.
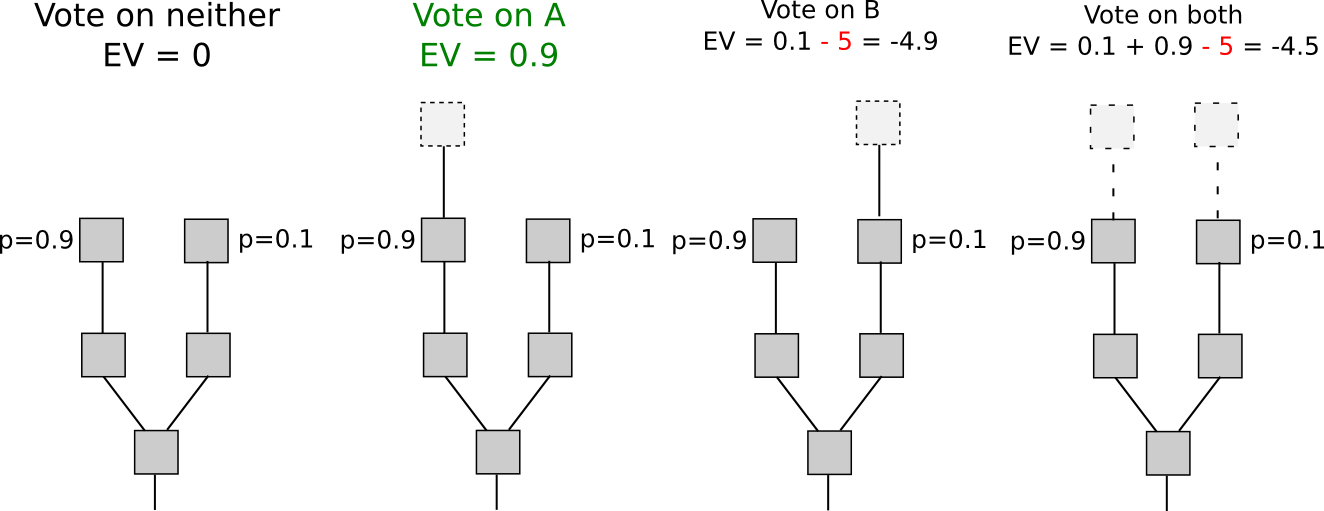
Proof of work has a nice property that makes it much simpler to design effective algorithms for it: participation in the economic set requires the consumption of a resource external to the system. This means that, when contributing one’s work to the blockchain, a miner must make the choice of which of all possible forks to contribute to (or whether to try to start a new fork), and the different options are mutually exclusive. Double-voting, including double-voting where the second vote is made many years after the first, is unprofitablem since it requires you to split your mining power among the different votes; the dominant strategy is always to put your mining power exclusively on the fork that you think is most likely to win.

With proof of stake, however, the situation is different. Although inclusion into the economic set may be costly (although as we will see it not always is), voting is free. This means that “naive proof of stake” algorithms, which simply try to copy proof of work by making every coin a “simulated mining rig” with a certain chance per second of making the account that owns it usable for signing a block, have a fatal flaw: if there are multiple forks, the optimal strategy is to vote on all forks at once. This is the core of “nothing at stake”.

Note that there is one argument for why it might not make sense for a user to vote on one fork in a proof-of-stake environment: “altruism-prime”. Altruism-prime is essentially the combination of actual altruism (on the part of users or software developers), expressed both as a direct concern for the welfare of others and the network and a psychological moral disincentive against doing something that is obviously evil (double-voting), as well as the “fake altruism” that occurs because holders of coins have a desire not to see the value of their coins go down.
Unfortunately, altruism-prime cannot be relied on exclusively, because the value of coins arising from protocol integrity is a public good and will thus be undersupplied (eg. if there are 1000 stakeholders, and each of their activity has a 1% chance of being “pivotal” in contributing to a successful attack that will knock coin value down to zero, then each stakeholder will accept a bribe equal to only 1% of their holdings). In the case of a distribution equivalent to the Ethereum genesis block, depending on how you estimate the probability of each user being pivotal, the required quantity of bribes would be equal to somewhere between 0.3% and 8.6% of total stake (or even less if an attack is nonfatal to the currency). However, altruism-prime is still an important concept that algorithm designers should keep in mind, so as to take maximal advantage of in case it works well.
Short and Long Range
If we focus our attention specifically on short-range forks – forks lasting less than some number of blocks, perhaps 3000, then there actually is a solution to the nothing at stake problem: security deposits. In order to be eligible to receive a reward for voting on a block, the user must put down a security deposit, and if the user is caught either voting on multiple forks then a proof of that transaction can be put into the original chain, taking the reward away. Hence, voting for only a single fork once again becomes the dominant strategy.

Another set of strategies, called “Slasher 2.0″ (in contrast to Slasher 1.0, the original security deposit-based proof of stake algorithm), involves simply penalizing voters that vote on the wrong fork, not voters that double-vote. This makes analysis substantially simpler, as it removes the need to pre-select voters many blocks in advance to prevent probabilistic double-voting strategies, although it does have the cost that users may be unwilling to sign anything if there are two alternatives of a block at a given height. If we want to give users the option to sign in such circumstances, a variant of logarithmic scoring rules can be used (see here for more detailed investigation). For the purposes of this discussion, Slasher 1.0 and Slasher 2.0 have identical properties.
The reason why this only works for short-range forks is simple: the user has to have the right to withdraw the security deposit eventually, and once the deposit is withdrawn there is no longer any incentive not to vote on a long-range fork starting far back in time using those coins. One class of strategies that attempt to deal with this is making the deposit permanent, but these approaches have a problem of their own: unless the value of a coin constantly grows so as to continually admit new signers, the consensus set ends up ossifying into a sort of permanent nobility. Given that one of the main ideological grievances that has led to cryptocurrency’s popularity is precisely the fact that centralization tends to ossify into nobilities that retain permanent power, copying such a property will likely be unacceptable to most users, at least for blockchains that are meant to be permanent. A nobility model may well be precisely the correct approach for special-purpose ephemeral blockchains that are meant to die quickly (eg. one might imagine such a blockchain existing for a round of a blockchain-based game).
One class of approaches at solving the problem is to combine the Slasher mechanism described above for short-range forks with a backup, transactions-as-proof-of-stake, for long range forks. TaPoS essentially works by counting transaction fees as part of a block’s “score” (and requiring every transaction to include some bytes of a recent block hash to make transactions not trivially transferable), the theory being that a successful attack fork must spend a large quantity of fees catching up. However, this hybrid approach has a fundamental flaw: if we assume that the probability of an attack succeeding is near-zero, then every signer has an incentive to offer a service of re-signing all of their transactions onto a new blockchain in exchange for a small fee; hence, a zero probability of attacks succeeding is not game-theoretically stable. Does every user setting up their own node.js webapp to accept bribes sound unrealistic? Well, if so, there’s a much easier way of doing it: sell old, no-longer-used, private keys on the black market. Even without black markets, a proof of stake system would forever be under the threat of the individuals that originally participated in the pre-sale and had a share of genesis block issuance eventually finding each other and coming together to launch a fork.
Because of all the arguments above, we can safely conclude that this threat of an attacker building up a fork from arbitrarily long range is unfortunately fundamental, and in all non-degenerate implementations the issue is fatal to a proof of stake algorithm’s success in the proof of work security model. However, we can get around this fundamental barrier with a slight, but nevertheless fundamental, change in the security model.
Weak Subjectivity
Although there are many ways to categorize consensus algorithms, the division that we will focus on for the rest of this discussion is the following. First, we will provide the two most common paradigms today:
- Objective: a new node coming onto the network with no knowledge except (i) the protocol definition and (ii) the set of all blocks and other “important” messages that have been published can independently come to the exact same conclusion as the rest of the network on the current state.
- Subjective: the system has stable states where different nodes come to different conclusions, and a large amount of social information (ie. reputation) is required in order to participate.
Systems that use social networks as their consensus set (eg. Ripple) are all necessarily subjective; a new node that knows nothing but the protocol and the data can be convinced by an attacker that their 100000 nodes are trustworthy, and without reputation there is no way to deal with that attack. Proof of work, on the other hand, is objective: the current state is always the state that contains the highest expected amount of proof of work.
Now, for proof of stake, we will add a third paradigm:
- Weakly subjective: a new node coming onto the network with no knowledge except (i) the protocol definition, (ii) the set of all blocks and other “important” messages that have been published and (iii) a state from less than N blocks ago that is known to be valid can independently come to the exact same conclusion as the rest of the network on the current state, unless there is an attacker that permanently has more than X percent control over the consensus set.
Under this model, we can clearly see how proof of stake works perfectly fine: we simply forbid nodes from reverting more than N blocks, and set N to be the security deposit length. That is to say, if state S has been valid and has become an ancestor of at least N valid states, then from that point on no state S’ which is not a descendant of S can be valid. Long-range attacks are no longer a problem, for the trivial reason that we have simply said that long-range forks are invalid as part of the protocol definition. This rule clearly is weakly subjective, with the added bonus that X = 100% (ie. no attack can cause permanent disruption unless it lasts more than N blocks).
Another weakly subjective scoring method is exponential subjective scoring, defined as follows:
- Every state S maintains a “score” and a “gravity”
score(genesis) = 0,gravity(genesis) = 1score(block) = score(block.parent) + weight(block) * gravity(block.parent), whereweight(block)is usually 1, though more advanced weight functions can also be used (eg. in Bitcoin,weight(block) = block.difficultycan work well)- If a node sees a new block
B'withBas parent, then ifnis the length of the longest chain of descendants fromBat that time,gravity(B') = gravity(B) * 0.99 ^ n(note that values other than 0.99 can also be used).

Essentially, we explicitly penalize forks that come later. ESS has the property that, unlike more naive approaches at subjectivity, it mostly avoids permanent network splits; if the time between the first node on the network hearing about block B and the last node on the network hearing about block B is an interval of k blocks, then a fork is unsustainable unless the lengths of the two forks remain forever within roughly k percent of each other (if that is the case, then the differing gravities of the forks will ensure that half of the network will forever see one fork as higher-scoring and the other half will support the other fork). Hence, ESS is weakly subjective with X roughly corresponding to how close to a 50/50 network split the attacker can create (eg. if the attacker can create a 70/30 split, then X = 0.29).
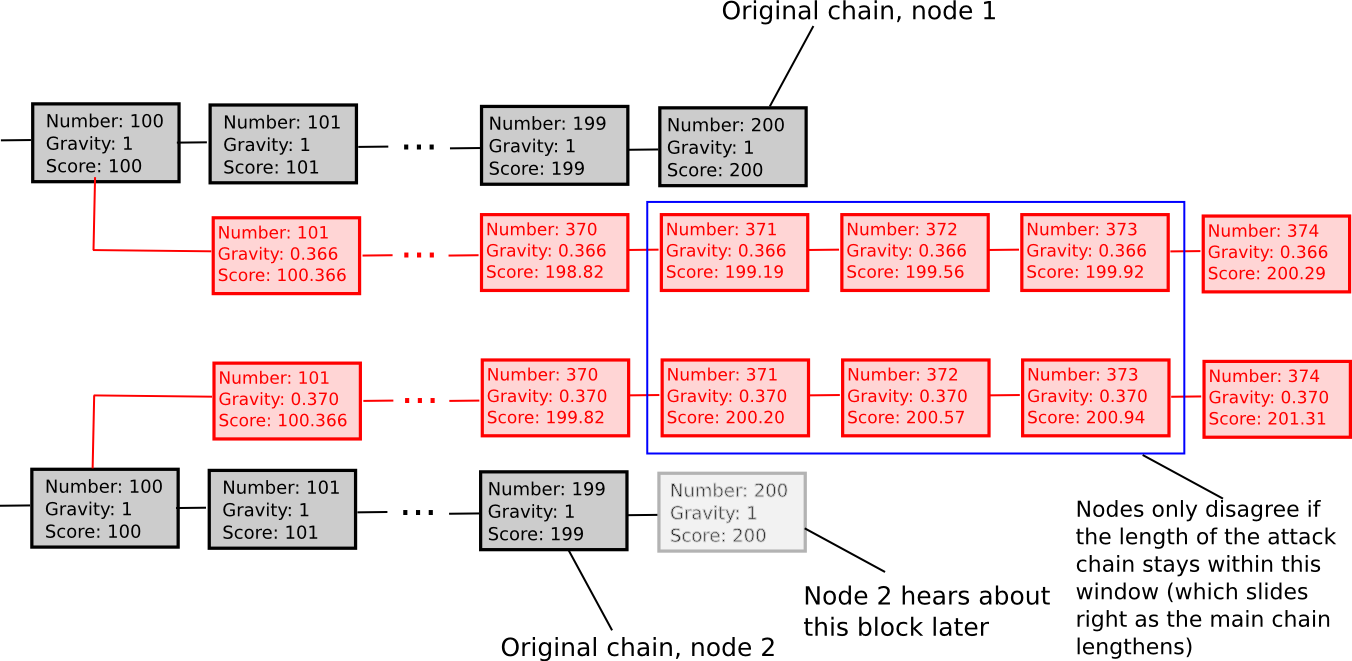
In general, the “max revert N blocks” rule is superior and less complex, but ESS may prove to make more sense in situations where users are fine with high degrees of subjectivity (ie. N being small) in exchange for a rapid ascent to very high degrees of security (ie. immune to a 99% attack after N blocks).
Consequences
So what would a world powered by weakly subjective consensus look like? First of all, nodes that are always online would be fine; in those cases weak subjectivity is by definition equivalent to objectivity. Nodes that pop online once in a while, or at least once every N blocks, would also be fine, because they would be able to constantly get an updated state of the network. However, new nodes joining the network, and nodes that appear online after a very long time, would not have the consensus algorithm reliably protecting them. Fortunately, for them, the solution is simple: the first time they sign up, and every time they stay offline for a very very long time, they need only get a recent block hash from a friend, a blockchain explorer, or simply their software provider, and paste it into their blockchain client as a “checkpoint”. They will then be able to securely update their view of the current state from there.
This security assumption, the idea of “getting a block hash from a friend”, may seem unrigorous to many; Bitcoin developers often make the point that if the solution to long-range attacks is some alternative deciding mechanism X, then the security of the blockchain ultimately depends on X, and so the algorithm is in reality no more secure than using X directly – implying that most X, including our social-consensus-driven approach, are insecure.
However, this logic ignores why consensus algorithms exist in the first place. Consensus is a social process, and human beings are fairly good at engaging in consensus on our own without any help from algorithms; perhaps the best example is the Rai stones, where a tribe in Yap essentially maintained a blockchain recording changes to the ownership of stones (used as a Bitcoin-like zero-intrinsic-value asset) as part of its collective memory. The reason why consensus algorithms are needed is, quite simply, because humans do not have infinite computational power, and prefer to rely on software agents to maintain consensus for us. Software agents are very smart, in the sense that they can maintain consensus on extremely large states with extremely complex rulesets with perfect precision, but they are also very ignorant, in the sense that they have very little social information, and the challenge of consensus algorithms is that of creating an algorithm that requires as little input of social information as possible.
Weak subjectivity is exactly the correct solution. It solves the long-range problems with proof of stake by relying on human-driven social information, but leaves to a consensus algorithm the role of increasing the speed of consensus from many weeks to twelve seconds and of allowing the use of highly complex rulesets and a large state. The role of human-driven consensus is relegated to maintaining consensus on block hashes over long periods of time, something which people are perfectly good at. A hypothetical oppressive government which is powerful enough to actually cause confusion over the true value of a block hash from one year ago would also be powerful enough to overpower any proof of work algorithm, or cause confusion about the rules of blockchain protocol.
Note that we do not need to fix N; theoretically, we can come up with an algorithm that allows users to keep their deposits locked down for longer than N blocks, and users can then take advantage of those deposits to get a much more fine-grained reading of their security level. For example, if a user has not logged in since T blocks ago, and 23% of deposits have term length greater than T, then the user can come up with their own subjective scoring function that ignores signatures with newer deposits, and thereby be secure against attacks with up to 11.5% of total stake. An increasing interest rate curve can be used to incentivize longer-term deposits over shorter ones, or for simplicity we can just rely on altruism-prime.
Marginal Cost: The Other Objection
One objection to long-term deposits is that it incentivizes users keeping their capital locked up, which is inefficient, the exact same problem as proof of work. However, there are three counterpoints to this. First, marginal cost is not total cost, and the ratio of total cost divided by marginal cost is much less for proof of stake than proof of work.
A user will likely experience close to no pain from locking up 50% of their capital for a few months, a slight amount of pain from locking up 70%, but would find locking up more than 85% intolerable without a large reward. Additionally, different users have very different preferences for how willing they are to lock up capital. Because of these two factors put together, regardless of what the equilibrium interest rate ends up being the vast majority of the capital will be locked up at far below marginal cost.
Fortunately, there is a way to test those assumptions: launch a proof of stake coin with a stake reward of 1%, 2%, 3%, etc per year, and see just how large a percentage of coins become deposits in each case. Users will not act against their own interests, so we can simply use the quantity of funds spent on consensus as a proxy for how much inefficiency the consensus algorithm introduces; if proof of stake has a reasonable level of security at a much lower reward level than proof of work, then we know that proof of stake is a more efficient consensus mechanism, and we can use the levels of participation at different reward levels to get an accurate idea of the ratio between total cost and marginal cost. Ultimately, it may take years to get an exact idea of just how large these costs are.
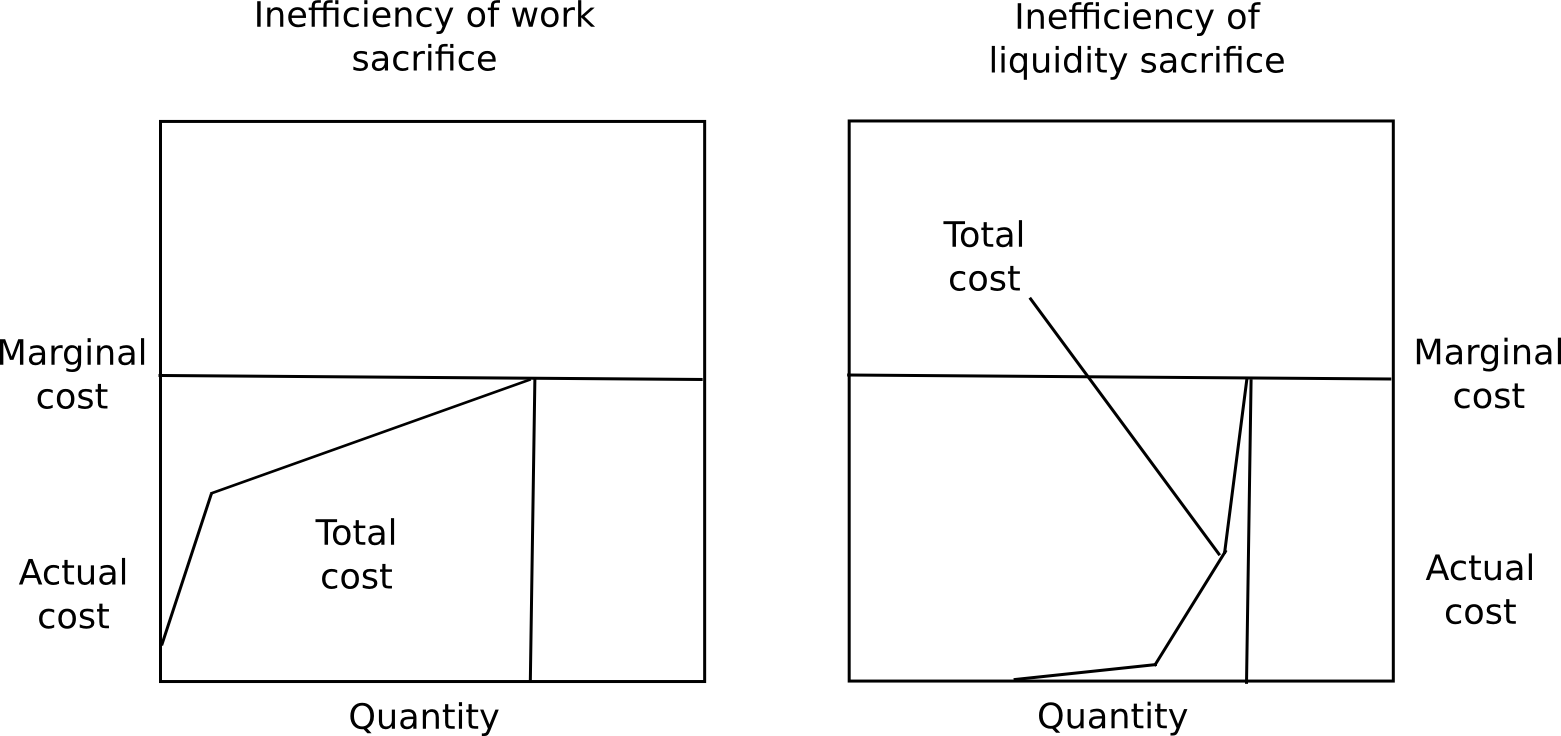
Second, locking up capital is a private cost, but an equally strong public good. The presence of locked up capital means that there is less money supply available for transactional purposes, and so the value of the currency will increase, redistributing the capital to everyone else. Third, security deposits are a very safe store of value, so (i) they substitute the use of money as a personal crisis insurance tool, and (ii) many users will be able to take out loans in the same currency collateralized by the security deposit.
As a conclusion, we now know for certain that (i) proof of stake algorithms can be made secure, and weak subjectivity is both sufficient and necessary as a fundamental change in the security model to sidestep nothing-at-stake concerns, and (ii) there are substantial economic reasons to believe that proof of stake actually is much more economically efficient than proof of work. Proof of stake is not an unknown; the past six months of formalization and research have determined exactly where the strengths and weaknesses lie, at least to as large extent as with proof of work, where mining centralization uncertainties may well forever abound. Now, it’s simply a matter of standardizing the algorithms, and giving blockchain developers the choice.
The post Proof of Stake: How I Learned to Love Weak Subjectivity appeared first on ethereum blog.
Sponsored by http://RBBI.co — a trusted name in precious metals Donate: https://blockchain.info/address/1LAYuQq6f11HccBgbe6bx8DiwKwzuYkPR3 Subscribe: http://patreon.com/madbitcoins … Categories : Bitcoins.
ethereum – Google Blogsuche
One of the latest ideas that has come to recently achieve some prominence in parts of the Bitcoin community is the line of thinking that has been described by both myself and others as “Bitcoin dominance maximalism” or just “Bitcoin maximalism” for short – essentially, the idea that an environment of multiple competing cryptocurrencies is undesirable, that it is wrong to launch “yet another coin”, and that it is both righteous and inevitable that the Bitcoin currency comes to take a monopoly position in the cryptocurrency scene. Note that this is distinct from a simple desire to support Bitcoin and make it better; such motivations are unquestionably beneficial and I personally continue to contribute to Bitcoin regularly via my python library pybitcointools. Rather, it is a stance that building something on Bitcoin is the only correct way to do things, and that doing anything else is unethical (see this post for a rather hostile example). Bitcoin maximalists often use “network effects” as an argument, and claim that it is futile to fight against them. However, is this ideology actually such a good thing for the cryptocurrency community? And is its core claim, that network effects are a powerful force strongly favoring the eventual dominance of already established currencies, really correct, and even if it is, does that argument actually lead where its adherents think it leads?
The Technicals
First, an introduction to the technical strategies at hand. In general, there are three approaches to creating a new crypto protocol:
- Build on Bitcoin the blockchain, but not Bitcoin the currency (metacoins, eg. most features of Counterparty)
- Build on Bitcoin the currency, but not Bitcoin the blockchain (sidechains)
- Create a completely standalone platform
Meta-protocols are relatively simple to describe: they are protocols that assign a secondary meaning to certain kinds of specially formatted Bitcoin transactions, and the current state of the meta-protocol can be determined by scanning the blockchain for valid metacoin transactions and sequentially processing the valid ones. The earliest meta-protocol to exist was Mastercoin; Counterparty is a newer one. Meta-protocols make it much quicker to develop a new protocol, and allow protocols to benefit directly from Bitcoin’s blockchain security, although at a high cost: meta-protocols are not compatible with light client protocols, so the only efficient way to use a meta-protocol is via a trusted intermediary.
Sidechains are somewhat more complicated. The core underlying idea revolves around a “two-way-pegging” mechanism, where a “parent chain” (usually Bitcoin) and a “sidechain” share a common currency by making a unit of one convertible into a unit of the other. The way it works is as follows. First, in order to get a unit of side-coin, a user must send a unit of parent-coin into a special “lockbox script”, and then submit a cryptographic proof that this transaction took place into the sidechain. Once this transaction confirms, the user has the side-coin, and can send it at will. When any user holding a unit of side-coin wants to convert it back into parent-coin, they simply need to destroy the side-coin, and then submit a proof that this transaction took place to a lockbox script on the main chain. The lockbox script would then verify the proof, and if everything checks out it would unlock the parent-coin for the submitter of the side-coin-destroying transaction to spend.

Unfortunately, it is not practical to use the Bitcoin blockchain and currency at the same time; the basic technical reason is that nearly all interesting metacoins involve moving coins under more complex conditions than what the Bitcoin protocol itself supports, and so a separate “coin” is required (eg. MSC in Mastercoin, XCP in Counterparty). As we will see, each of these approaches has its own benefits, but it also has its own flaws. This point is important; particularly, note that many Bitcoin maximalists’ recent glee at Counterparty forking Ethereum was misplaced, as Counterparty-based Ethereum smart contracts cannot manipulate BTC currency units, and the asset that they are instead likely to promote (and indeed already have promoted) is the XCP.
Network Effects
Now, let us get to the primary argument at play here: network effects. In general, network effects can be defined simply: a network effect is a property of a system that makes the system intrinsically more valuable the more people use it. For example, a language has a strong network effect: Esperanto, even if it is technically superior to English in the abstract, is less useful in practice because the whole point of a language is to communicate with other people and not many other people speak Esperanto. On the other hand, a single road has a negative network effect: the more people use it the more congested it becomes.
In order to properly understand what network effects are at play in the cryptoeconomic context, we need to understand exactly what these network effects are, and exactly what thing each effect is attached to. Thus, to start off, let us list a few of the major ones (see here and here for primary sources):
{kind=link}
- Security effect: systems that are more widely adopted derive their consensus from larger consensus groups, making them more difficult to attack.
- Payment system network effect: payment systems that are accepted by more merchants are more attractive to consumers, and payment systems used by more consumers are more attractive to merchants.
- Developer network effect: there are more people interested in writing tools that work with platforms that are widely adopted, and the greater number of these tools will make the platform easier to use.
- Integration network effect: third party platforms will be more willing to integrate with a platform that is widely adopted, and the greater number of these tools will make the platform easier to use.
- Size stability effect: currencies with larger market cap tend to be more stable, and more established cryptocurrencies are seen as more likely (and therefore by self-fulfilling-prophecy actually are more likely) to remain at nonzero value far into the future.
- Unit of account network effect: currencies that are very prominent, and stable, are used as a unit of account for pricing goods and services, and it is cognitively easier to keep track of one’s funds in the same unit that prices are measured in.
- Market depth effect: larger currencies have higher market depth on exchanges, allowing users to convert larger quantities of funds in and out of that currency without taking a hit on the market price.
- Market spread effect: larger currencies have higher liquidity (ie. lower spread) on exchanges, allowing users to convert back and forth more efficiently.
- Intrapersonal single-currency preference effect: users that already use a currency for one purpose prefer to use it for other purposes both due to lower cognitive costs and because they can maintain a lower total liquid balance among all cryptocurrencies without paying interchange fees.
- Interpersonal single-currency preference effect: users prefer to use the same currency that others are using to avoid interchange fees when making ordinary transactions
- Marketing network effect: things that are used by more people are more prominent and thus more likely to be seen by new users. Additionally, users have more knowledge about more prominent systems and thus are less concerned that they might be exploited by unscrupulous parties selling them something harmful that they do not understand.
- Regulatory legitimacy network effect: regulators are less likely to attack something if it is prominent because they will get more people angry by doing so
The first thing that we see is that these network effects are actually rather neatly split up into several categories: blockchain-specific network effects (1), platform-specific network effects (2-4), currency-specific network effects (5-10), and general network effects (11-12), which are to a large extent public goods across the entire cryptocurrency industry. There is a substantial opportunity for confusion here, since Bitcoin is simultaneously a blockchain, a currency and a platform, but it is important to make a sharp distinction between the three. The best way to delineate the difference is as follows:
- A currency is something which is used as a medium of exchange or store of value; for example, dollars, BTC and DOGE.
- A platform is a set of interoperating tools and infrastructure that can be used to perform certain tasks; for currencies, the basic kind of platform is the collection of a payment network and the tools needed to send and receive transactions in that network, but other kinds of platforms may also emerge.
- A blockchain is a consensus-driven distributed database that modifies itself based on the content of valid transactions according to a set of specified rules; for example, the Bitcoin blockchain, the Litecoin blockchain, etc.
To see how currencies and platforms are completely separate, the best example to use is the world of fiat currencies. Credit cards, for example, are a highly multi-currency platform. Someone with a credit card from Canada tied to a bank account using Canadian dollars can spend funds at a merchant in Switzerland accepting Swiss francs, and both sides barely know the difference. Meanwhile, even though both are (or at least can be) based on the US dollar, cash and Paypal are completely different platforms; a merchant accepting only cash will have a hard time with a customer who only has a Paypal account.
As for how platforms and blockchains are separate, the best example is the Bitcoin payment protocol and proof of existence. Although the two use the same blockchain, they are completely different applications, users of one have no idea how to interpret transactions associated with the other, and it is relatively easy to see how they benefit from completely different network effects so that one can easily catch on without the other. Note that protocols like proof of existence and Factom are mostly exempt from this discussion; their purpose is to embed hashes into the most secure available ledger, and while a better ledger has not materialized they should certainly use Bitcoin, particularly because they can use Merkle trees to compress a large number of proofs into a single hash in a single transaction.
Network Effects and Metacoins
Now, in this model, let us examine metacoins and sidechains separately. With metacoins, the situation is simple: metacoins are built on Bitcoin the blockchain, and not Bitcoin the platform or Bitcoin the currency. To see the former, note that users need to download a whole new set of software packages in order to be able to process Bitcoin transactions. There is a slight cognitive network effect from being able to use the same old infrastructure of Bitcoin private/public key pairs and addresses, but this is a network effect for the combination of ECDSA, SHA256+RIPEMD160 and base 58 and more generally the whole concept of cryptocurrency, not the Bitcoin platform; Dogecoin inherits exactly the same gains. To see the latter, note that, as mentioned above, Counterparty has its own internal currency, the XCP. Hence, metacoins benefit from the network effect of Bitcoin’s blockchain security, but do not automatically inherit all of the platform-specific and currency-specific network effects.
Of course, metacoins’ departure from the Bitcoin platform and Bitcoin currency is not absolute. First of all, even though Counterparty is not “on” the Bitcoin platform, it can in a very meaningful sense be said to be “close” to the Bitcoin platform – one can exchange back and forth between BTC and XCP very cheaply and efficiently. Cross-chain centralized or decentralized exchange, while possible, is several times slower and more costly. Second, some features of Counterparty, particularly the token sale functionality, do not rely on moving currency units under any conditions that the Bitcoin protocol does not support, and so one can use that functionality without ever purchasing XCP, using BTC directly. Finally, transaction fees in all metacoins can be paid in BTC, so in the case of purely non-financial applications metacoins actually do fully benefit from Bitcoin’s currency effect, although we should note that in most non-financial cases developers are used to messaging being free, so convincing anyone to use a non-financial blockchain dapp at $ 0.05 per transaction will likely be an uphill battle.
In some of these applications – particularly, perhaps to Bitcoin maximalists’ chagrin, Counterparty’s crypto 2.0 token sales, the desire to move back and forth quickly to and from Bitcoin, as well as the ability to use it directly, may indeed create a platform network effect that overcomes the loss of secure light client capability and potential for blockchain speed and scalability upgrades, and it is in these cases that metacoins may find their market niche. However, metacoins are most certainly not an all-purpose solution; it is absurd to believe that Bitcoin full nodes will have the computational ability to process every single crypto transaction that anyone will ever want to do, and so eventually movement to either scalable architectures or multichain environments will be necessary.
Network Effects and Sidechains
Sidechains have the opposite properties of metacoins. They are built on Bitcoin the currency, and thus benefit from Bitcoin’s currency network effects, but they are otherwise exactly identical to fully independent chains and have the same properties. This has several pros and cons. On the positive side, it means that, although “sidechains” by themselves are not a scalability solution as they do not solve the security problem, future advancements in multichain, sharding or other scalability strategies are all open to them to adopt.
On the negative side, however, they do not benefit from Bitcoin’s platform network effects. One must download special software in order to be able to interact with a sidechain, and one must explicitly move one’s bitcoins onto a sidechain in order to be able to use it – a process wich is equally as difficult as converting them into a new currency in a new network via a decentralized exchange. In fact, Blockstream employees have themselves admitted that the process for converting side-coins back into bitcoins is relatively inefficient, to the point that most people seeking to move their bitcoins there and back will in fact use exactly the same centralized or decentralized exchange processes as would be used to migrate to a different currency on an independent blockchain.
Additionally, note that there is one security approach that independent networks can use which is not open to sidechains: proof of stake. The reasons for this are twofold. First one of the key arguments in favor of proof of stake is that even a successful attack against proof of stake will be costly for the attacker, as the attacker will need to keep his currency units deposited and watch their value drop drastically as the market realizes that the coin is compromised. This incentive effect does not exist if the only currency inside of a network is pegged to an external asset whose value is not so closely tied to that network’s success.
Second, proof of stake gains much of its security because the process of buying up 50% of a coin in order to mount a takeover attack will itself increase the coin’s price drastically, making the attack even more expensive for the attacker. In a proof of stake sidechain, however, one can easily move a very large quantity of coins into a chain from the parent chain, an mount the attack without moving the asset price at all. Note that both of these arguments continue to apply even if Bitcoin itself upgrades to proof of stake for its security. Hence, if you believe that proof of stake is the future, then both metacoins and sidechains (or at least pure sidechains) become highly suspect, and thus for that purely technical reason Bitcoin maximalism (or, for that matter, ether maximalism, or any other kind of currency maximalism) becomes dead in the water.
Currency Network Effects, Revisited
Altogether, the conclusion from the above two points is twofold. First, there is no universal and scalable approach that allows users to benefit from Bitcoin’s platform network effects. Any software solution that makes it easy for Bitcoin users to move their funds to sidechains can be easily converted into a solution that makes it just as easy for Bitcoin users to convert their funds into an independent currency on an independent chain. On the other hand, however, currency network effects are another story, and may indeed prove to be a genuine advantage for Bitcoin-based sidechains over fully independent networks. So, what exactly are these effects and how powerful is each one in this context? Let us go through them again:
- Size-stability network effect (larger currencies are more stable) – this network effect is legitimate, and Bitcoin has been shown to be less volatile than smaller coins.
- Unit of account network effect (very large currencies become units of account, leading to more purchasing power stability via price stickiness as well as higher salience) – unfortunately, Bitcoin will likely never be stable enough to trigger this effect; the best empirical evidence we can see for this is likely the valuation history of gold.
- Market depth effect (larger currencies support larger transactions without slippage and have a lower bid/ask spread) – these effect are legitimate up to a point, but then beyond that point (perhaps a market cap of $ 10-$ 100M), the market depth is imply good enough and the spread is low enough for nearly all types of transactions, and the benefit from further gains is small.
- Single-currency preference effect (people prefer to deal with fewer currencies, and prefer to use the same currencies that others are using) – the intrapersonal and interpersonal parts to this effect are legitimate, but we note that (i) the intrapersonal effect only applies within individual people, not between people, so it does not prevent an ecosystem with multiple preferred global currencies from existing, and (ii) the interpersonal effect is small as interchange fees especially in crypto tend to be very low, less than 0.30%, and will likely go down to essentially zero with decentralized exchange.
{kind=link}
Hence, the single-currency preference effect is likely the largest concern, followed by the size stability effects, whereas the market depth effects are likely relatively tiny once a cryptocurrency gets to a substantial size. However, it is important to note that the above points have several major caveats. First, if (1) and (2) dominate, then we know of explicit strategies for making a new coin that is even more stable than Bitcoin even at a smaller size; thus, they are certainly not points in Bitcoin’s favor.
Second, those same strategies (particularly the exogenous ones) can actually be used to create a stable coin that is pegged to a currency that has vastly larger network effects than even Bitcoin itself; namely, the US dollar. The US dollar is thousands of times larger than Bitcoin, people are already used to thinking in terms of it, and most importantly of all it actually maintains its purchasing power at a reasonable rate in the short to medium term without massive volatility. Employees of Blockstream, the company behind sidechains, have often promoted sidechains under the slogan “innovation without speculation“; however, the slogan ignores that Bitcoin itself is quite speculative and as we see from the experience of gold always will be, so seeking to install Bitcoin as the only cryptoasset essentially forces all users of cryptoeconomic protocols to participate in speculation. Want true innovation without speculation? Then perhaps we should all engage in a little US dollar stablecoin maximalism instead.
Finally, in the case of transaction fees specifically, the intrapersonal single-currency preference effect arguably disappears completely. The reason is that the quantities involved are so small ($ 0.01-$ 0.05 per transaction) that a dapp can simply siphon off $ 1 from a user’s Bitcoin wallet at a time as needed, not even telling the user that other currencies exist, thereby lowering the cognitive cost of managing even thousands of currencies to zero. The fact that this token exchange is completely non-urgent also means that the client can even serve as a market maket while moving coins from one chain to the other, perhaps even earning a profit on the currency interchange bid/ask spread. Furthermore, because the user does not see gains and losses, and the user’s average balance is so low that the central limit theorem guarantees with overwhelming probability that the spikes and drops will mostly cancel each other out, stability is also fairly irrelevant. Hence, we can make the point that alternative tokens which are meant to serve primarily as “cryptofuels” do not suffer from currency-specific network effect deficiencies at all. Let a thousand cryptofuels bloom.
Incentive and Psychological Arguments
There is another class of argument, one which may perhaps be called a network effect but not completely, for why a service that uses Bitcoin as a currency will perform better: the incentivized marketing of the Bitcoin community. The argument goes as follows. Services and platforms based on Bitcoin the currency (and to a slight extent services based on Bitcoin the platform) increase the value of Bitcoin. Hence, Bitcoin holders would personally benefit from the value of their BTC going up if the service gets adopted, and are thus motivated to support it.
This effect occurs on two levels: the individual and the corporate. The corporate effect is a simple matter of incentives; large businesses will actually support or even create Bitcoin-based dapps to increase Bitcoin’s value, simply because they are so large that even the portion of the benefit that personally accrues to themselves is enough to offset the costs; this is the “speculative philanthropy” strategy described by Daniel Krawisz.
The individual effect is not so much directly incentive-based; each individual’s ability to affect Bitcoin’s value is tiny. Rather, it’s more a clever exploitation of psychological biases. It’s well-known that people tend to change their moral values to align with their personal interests, so the channel here is more complex: people who hold BTC start to see it as being in the common interest for Bitcoin to succeed, and so they will genuinely and excitedly support such applications. As it turns out, even a small amount of incentive suffices to shift over people’s moral values to such a large extent, creating a psychological mechanism that manages to overcome not just the coordination problem but also, to a weak extent, the public goods problem.
There are several major counterarguments to this claim. First, it is not at all clear that the total effect of the incentive and psychological mechanisms actually increases as the currency gets larger. Although a larger size leads to more people affected by the incentive, a smaller size creates a more concentrated incentive, as people actually have the opportunity to make a substantial difference to the success of the project. The tribal psychology behind incentive-driven moral adjustment may well be stronger for small “tribes” where individuals also have strong social connections to each other than larger tribes where such connections are more diffuse; this is somewhat similar to the Gemeinschaft vs Gesellschaft distinction in sociology. Perhaps a new protocol needs to have a concentrated set of highly incentivized stakeholders in order to seed a community, and Bitcoin maximalists are wrong to try to knock this ladder down after Bitcoin has so beautifully and successfully climbed up it. In any case, all of the research around optimum currency areas will have to be heavily redone in the context of the newer volatile cryptocurrencies, and the results may well go down either way.
Second, the ability for a network to issue units of a new coin has been proven to be a highly effective and successful mechanism for solving the public goods problem of funding protocol development, and any platform that does not somehow take advantage of the seignorage revenue from creating a new coin is at a substantial disadvantage. So far, the only major crypto 2.0 protocol-building company that has successfully funded itself without some kind of “pre-mine” or “pre-sale” is Blockstream (the company behind sidechains), which recently received $ 21 million of venture capital funding from Silicon Valley investors. Given Blockstream’s self-inflicted inability to monetize via tokens, we are left with three viable explanations for how investors justified the funding:
- The funding was essentially an act of speculative philathropy on the part of Silicon Valley venture capitalists looking to increase the value of their BTC and their other BTC-related investments.
- Blockstream intends to earn revenue by taking a cut of the fees from their blockchains (non-viable because the public will almost certainly reject such a clear and blatant centralized siphoning of resources even more virulently then they would reject a new currency)
- Blockstream intends to “sell services”, ie. follow the RedHat model (viable for them but few others; note that the total room in the market for RedHat-style companies is quite small)
Both (1) and (3) are highly problematic; (3) because it means that few other companies will be able to follow its trail and because it gives them the incentive to cripple their protocols so they can provide centralized overlays, and (1) because it means that crypto 2.0 companies must all follow the model of sucking up to the particular concentrated wealthy elite in Silicon Valley (or maybe an alternative concentrated wealthy elite in China), hardly a healthy dynamic for a decentralized ecosystem that prides itself on its high degree of political independence and its disruptive nature.
Ironically enough, the only “independent” sidechain project that has so far announced itself, Truthcoin, has actually managed to get the best of both worlds: the project got on the good side of the Bitcoin maximalist bandwagon by announcing that it will be are a sidechain, but in fact the development team intends to introduce into the platform two “coins” – one of which will be a BTC sidechain token and the other an independent currency that is meant to be, that’s right, crowd-sold.
A New Strategy
Thus, we see that while currency network effects are sometimes moderately strong, and they will indeed exert a preference pressure in favor of Bitcoin over other existing cryptocurrencies, the creation of an ecosystem that uses Bitcoin exclusively is a highly suspect endeavor, and one that will lead to a total reduction and increased centralization of funding (as only the ultra-rich have sufficient concentrated incentive to be speculative philanthropists), closed doors in security (no more proof of stake), and is not even necessarily guaranteed to end with Bitcoin willing. So is there an alternative strategy that we can take? Are there ways to get the best of both worlds, simultaneously currency network effects and securing the benefits of new protocols launching their own coins?
As it turns out, there is: the dual-currency model. The dual-currency model, arguably pioneered by Robert Sams, although in various incarnations independently discovered by Bitshares, Truthcoin and myself, is at the core simple: every network will contain two (or even more) currencies, splitting up the role of medium of transaction and vehicle of speculation and stake (the latter two roles are best merged, because as mentioned above proof of stake works best when participants suffer the most from a fork). The transactional currency will be either a Bitcoin sidechain, as in Truthcoin’s model, or an endogenous stablecoin, or an exogenous stablecoin that benefits from the almighty currency network effect of the US dollar (or Euro or CNY or SDR or whatever else). Hayekian currency competition will determine which kind of Bitcoin, altcoin or stablecoin users prefer; perhaps sidechain technology can even be used to make one particular stablecoin transferable across many networks.
The vol-coin will be the unit of measurement of consensus, and vol-coins will sometimes be absorbed to issue new stablecoins when stablecoins are consumed to pay transaction fees; hence, as explainted in the argument in the linked article on stablecoins, vol-coins can be valued as a percentage of future transaction fees. Vol-coins can be crowd-sold, maintaining the benefits of a crowd sale as a funding mechanism. If we decide that explicit pre-mines or pre-sales are “unfair”, or that they have bad incentives because the developers’ gain is frontloaded, then we can instead use voting (as in DPOS) or prediction markets instead to distribute coins to developers in a decentralized way over time.
Another point to keep in mind is, what happens to the vol-coins themselves? Technological innovation is rapid, and if each network gets unseated within a few years, then the vol-coins may well never see substantial market cap. One answer is to solve the problem by using a clever combination of Satoshian thinking and good old-fashioned recursive punishment systems from the offline world: establish a social norm that every new coin should pre-allocate 50-75% of its units to some reasonable subset of the coins that came before it that directly inspired its creation, and enforce the norm blockchain-style – if your coin does not honor its ancestors, then its descendants will refuse to honor it, instead sharing the extra revenues between the originally cheated ancestors and themselves, and no one will fault them for that. This would allow vol-coins to maintain continuity over the generations. Bitcoin itself can be included among the list of ancestors for any new coin. Perhaps an industry-wide agreement of this sort is what is needed to promote the kind of cooperative and friendly evolutionary competition that is required for a multichain cryptoeconomy to be truly successful.
Would we have used a vol-coin/stable-coin model for Ethereum had such strategies been well-known six months ago? Quite possibly yes; unfortunately it’s too late to make the decision now at the protocol level, particularly since the ether genesis block distribution and supply model is essentially finalized. Fortunately, however, Ethereum allows users to create their own currencies inside of contracts, so it is entirely possible that such a system can simply be grafted on, albeit slightly unnaturally, over time. Even without such a change, ether itself will retain a strong and steady value as a cryptofuel, and as a store of value for Ethereum-based security deposits, simply because of the combination of the Ethereum blockchain’s network effect (which actually is a platform network effect, as all contracts on the Ethereum blockchain have a common interface and can trivially talk to each other) and the weak-currency-network-effect argument described for cryptofuels above preserves for it a stable position. For 2.0 multichain interaction, however, and for future platforms like Truthcoin, the decision of which new coin model to take is all too relevant.
The post On Bitcoin Maximalism, and Currency and Platform Network Effects appeared first on ethereum blog.
Kaum ein Altcoin wurde mit so viel Gedöns und Begeisterung verkündet wie Ethereum. Aber was ist dran an dem System, das, so die Medien, "alles" dezentralisieren will und über das schon gemunkelt wurde, es könne den …
ethereum – Google Blogsuche
Kaum ein Altcoin wurde mit so viel Gedöns und Begeisterung verkündet wie Ethereum. Aber was ist dran an dem System, das, so die Medien, “alles” dezentralisieren.
ethereum – Google Blogsuche
I’m Gavin Wood, a co-founder of Ethereum and, along with Vitalik Buterin and Jeffrey Wilcke, one of the three directors of the Eth Dev, the NFP organisation that is managing the development (under contract from Ethereum Suisse) of the Ethereum blockchain. This is a small update to let you all know what has been going on recently.
I sit here on an immaculate couch that has been zapped forward in time from the 1960s. It is in the room that will become the chillout & wind-down room of the heart of the (C++) Ethereum development operation. Surrounding me is Alex Leverington on a Bond villain’s easy chair, and Aeron Buchanan stuck behind a locker that looks as though it was an original prop from M*A*S*H. Lighting equipment from a Soviet Blade Runner, now forgotten except in Berlin’s coolest districts where renaissance chemistry and 60s luxury breath Frankensteinesque life into it, provides an unyielding glow to the work in progress. There is still much to be done here (I feel a little like I’m on the set of Challenge Anneka) but it is undeniably taking shape. This is thanks mostly to our own Anneka Rice, Sarah O’Neill, who is working around the clock to get this place ready for ÐΞVcon-0, our first developer symposium. Helping her, similarly around the clock, is the inimitable Roland, a hardened international interior outfitter whose memoirs I can’t wait to read.
On a personal note, I must say these last few months have been some of the busiest of my life. I spent the last couple of weeks between Switzerland and the UK, visiting Stephan, Ian and Louis. Despite the draws of the north of England, it’s nice to be back in Berlin; the combination of great burgers and cocktails, beautiful surroundings and nice people makes it difficult to leave. Awesome C++ coders are welcome to take that as a hint: we’re still hiring (-:
Technicals
During the last couple of weeks we’ve made a number of important revisions to the protocol, mostly provisions for creating light-client ÐApp nodes. There will be a directors’ post in due course detailing these, but suffice it to say we are as committed as ever that the Ethereum blockchain make possible the massively multi-user decentralised applications for all sizes of devices. The seventh in our proof-of-concept series is awaiting imminent release and the final in the series, PoC-8 will be starting development shortly.
Fresh meat
As time goes on, our team moves from strength to strength. I’m pleased to announce that Dr. Sven Ehlert has joined us. He will be leading development operations; cleaning up the build process, making the build as robust as possible, assisting Caktux in our CI systems and, most importantly, helping architect a stress-testing harness in which we’ll be simulating a series of extreme situations, measuring and analysing. He’s also a scrum aficionado and will be helping us streamline some of our development processes as our team grows.
It is with great pleasure I can also announce that Dr. Jutta Steiner will also be working closely with us in the capacity of managing our security audit. As well as being an enthusiastic ÐApp-developer, she comes with an excellent track record of handling projects and a superb understanding of not only this cutting edge technology but also the human processes that must go on behind it.
I must also shout out to Dr. Andreas Lubbe; though a long-time member of the Berlin Ethereum community and having worked on Ethereum-related code (a notable devotee of node.js), we have recently started working much more closely together on the secure Ethereum contract documentation (SECDoc) framework and the associated natural language specification format, NatSpec. I look forward to some great collaboration.
Aside from Lefteris, who began his first official day with us today (working with Christian on Solidity, and more specifically on the SECDoc and NatSpec portions of it), we have two new developers joining us: Yann Levreau and Arkadiy Paronyan. Yann, a recent arrival in Berlin from his native France will be joined by Arkadiy who is travelling all the way from Moscow to become part of the team. Both have substantial experience in C++ and related technologies and will be helping us flesh out the developer tools and in particular pave the way to the IDE vision.
Finally, I’m happy to report that Christoph Jentzsch, though originally joining us for only 2 months (while taking time out from his doctoral studies), will be joining the project full time in the new year and continuing his much appreciated work on our tests and the general C++ health and robustness.
ÐΞVcon-0
As time rushes by, Sarah, Roland and their team rush even more to finish our hub. For they know that come Monday the 24th, Berlin will have some new arrivals. Developers and collaborators from around the globe will descend on 37a Waldemarstraße, Berlin 10999 for a week of getting everybody on the same page. It is DEVcon-0: ethereum’s first developer symposium.
Conceived by myself and Jeff on a sleepy train from Zug to Zurich as a means of getting the Amsterdam/Go guys on the same page as the Berlin/C++ guys it has evolved into a showcase, set of seminars and workshops of all of ÐΞV, our technologies, our personnel and some of our close collaborators. It is a chance for us each to build lasting professional relationships and bond in what will become a project that may if not define, certainly form a hallmark, on our professional lifes.
Our hub will play host to around 40 people, the vast majority of which are accomplished technical minds that Jeff, myself or Vitalik has at one point or another mentioned, and for the period of a week we will be chatting, mingling and sharing our ideas, hopes and dreams for everything blockchain, decentralised and disruption related. It’s going to be awesome: look out for the videos!
Ever closer
Aside from the continuing work towards starting PoC-8 and the alpha series, I’m glad to report that the Solidity project storms onwards under the stewardship of Christian: the first contracts compiled with Solidity have been delivered and tested working on the testnet, and as I write this I see another Pull Request for state mappings. Great stuff.
Alex has also been working tirelessly on our crypto code and is now beginning work on the p2p layer, the full strategy for which we’ll be seeing in his address at ÐΞVcon. Marek and Marian have also been busy on the Javascript API, and I can assure any Javascript ÐApp developers that they will have a lot to look forward to in PoC-8.
Summing Up
There are also a few other developments and personnel I’d love to announce, but I fear, once again, it will have to wait until next time. Watch this space for a post-ÐΞVcon update!
Gav.
The post Gav’s Ethereum ÐΞV Update III appeared first on ethereum blog.
After the great success of the last Ethereum Introductory Workshop, round two is coming up! During the first part of the event, there will be an open coding.
ethereum – Google Blogsuche
Ethereum erfährt derzeit eine enorme Aufmerksamkeit in der Krypto-Cummunity. Dies liegt vor allem daran, dass hinter der Entwicklung das "Krypto-Wunderkind" Vitalik Buterin steht. Der 19jährige gilt als einer der klügsten …
ethereum – Google Blogsuche
Special thanks to Vlad Zamfir for much of the thinking behind multi-chain cryptoeconomic paradigms
First off, a history lesson. In October 2013, when I was visiting Israel as part of my trip around the Bitcoin world, I came to know the core teams behind the colored coins and Mastercoin projects. Once I properly understood Mastercoin and its potential, I was immediately drawn in by the sheer power of the protocol; however, I disliked the fact that the protocol was designed as a disparate ensemble of “features”, providing a subtantial amount of functionality for people to use, but offering no freedom to escape out of that box. Seeking to improve Mastercoin’s potential, I came up with a draft proposal for something called “ultimate scripting” – a general-purpose stack-based programming language that Mastercoin could include to allow two parties to make a contract on an arbitrary mathematical formula. The scheme would generalize savings wallets, contracts for difference, many kinds of gambling, among other features. It was still quite limited, allowing only three stages (open, fill, resolve) and no internal memory and being limited to 2 parties per contract, but it was the first true seed of the Ethereum idea.
I submitted the proposal to the Mastercoin team. They were impressed, but elected not to adopt it too quickly out of a desire to be slow and conservative; a philosophy which the project keeps to to this day and which David Johnston mentioned at the recent Tel Aviv conference as Mastercoin’s primary differentiating feature. Thus, I decided to go out on my own and simply build the thing myself. Over the next three weeks I created the original Ethereum whitepaper (unfortunately now gone, but a still very early version exists here). The basic building blocks were all there, except the progamming language was register-based instead of stack-based, and, because I was/am not skilled enough in p2p networking to build an independent blockchain client from scratch, it was to be built as a meta-protocol on top of Primecoin – not Bitcoin, because I wanted to satisfy the concerns of Bitcoin developers who were angry at meta-protocols bloating the blockchain with extra data.
Once competent developers like Gavin Wood and Jeffrey Wilcke, who did not share my deficiencies in ability to write p2p networking code, joined the project, and once enough people were excited that I saw there would be money to hire more, I made the decision to immediately move to an independent blockchain. The reasoning for this choice I described in my whitepaper in early January:
The advantage of a metacoin protocol is that it can allow for more advanced transaction types, including custom currencies, decentralized exchange, derivatives, etc, that are impossible on top of Bitcoin itself. However, metacoins on top of Bitcoin have one major flaw: simplified payment verification, already difficult with colored coins, is outright impossible on a metacoin. The reason is that while one can use SPV to determine that there is a transaction sending 30 metacoins to address X, that by itself does not mean that address X has 30 metacoins; what if the sender of the transaction did not have 30 metacoins to start with and so the transaction is invalid? Finding out any part of the current state essentially requires scanning through all transactions going back to the metacoin’s original launch to figure out which transactions are valid and which ones are not. This makes it impossible to have a truly secure client without downloading the entire 12 GB Bitcoin blockchain.
Essentially, metacoins don’t work for light clients, making them rather insecure for smartphones, users with old computers, internet-of-things devices, and once the blockchain scales enough for desktop users as well. Ethereum’s independent blockchain, on the other hand, is specifically designed with a highly advanced light client protocol; unlike with meta-protocols, contracts on top of Ethereum inherit the Ethereum blockchain’s light client-friendliness properties fully. Finally, long after that, I realized that by making an independent blockchain allows us to experiment with stronger versions of GHOST-style protocols, safely knocking down the block time to 12 seconds.
So what’s the point of this story? Essentially, had history been different, we easily could have gone the route of being “on top of Bitcoin” right from day one (in fact, we still could make that pivot if desired), but solid technical reasons existed then why we deemed it better to build an independent blockchain, and these reasons still exist, in pretty much exactly the same form, today.
Since a number of readers were expecting a response to how Ethereum as an independent blockchain would be useful even in the face of the recent announcement of a metacoin based on Ethereum technology, this is it. Scalability. If you use a metacoin on BTC, you gain the benefit of having easier back-and-forth interaction with the Bitcoin blockchain, but if you create an independent chain then you have the ability to achieve much stronger guarantees of security particularly for weak devices. There are certainly applications for which a higher degree of connectivity with BTC is important ; for these cases a metacoin would certainly be superior (although note that even an independent blockchain can interact with BTC pretty well using basically the same technology that we’ll describe in the rest of this blog post). Thus, on the whole, it will certainly help the ecosystem if the same standardized EVM is available across all platforms.
Beyond 1.0
However, in the long term, even light clients are an ugly solution. If we truly expect cryptoeconomic platforms to become a base layer for a very large amount of global infrastructure, then there may well end up being so many crypto-transactions altogether that no computer, except maybe a few very large server farms run by the likes of Google and Amazon, is powerful enough to process all of them. Thus, we need to break the fundamental barrier of cryptocurrency: that there need to exist nodes that process every transaction. Breaking that barrier is what gets a cryptoeconomic platform’s database from being merely massively replicated to being truly distributed. However, breaking the barrier is hard, particularly if you still want to maintain the requirement that all of the different parts of the ecosystem should reinforce each other’s security.
To achieve the goal, there are three major strategies:
- Building protocols on top of Ethereum that use Ethereum only as an auditing-backend-of-last-resort, conserving transaction fees.
- Turning the blockchain into something much closer to a high-dimensional interlinking mesh with all parts of the database reinforcing each other over time.
- Going back to a model of one-protocol (or one service)-per-chain, and coming up with mechanisms for the chains to (1) interact, and (2) share consensus strength.
Of these strategies, note that only (1) is ultimately compatible with keeping the blockchain in a form anything close to what the Bitcoin and Ethereum protocols support today. (2) requires a massive redesign of the fundamental infrastructure, and (3) requires the creation of thousands of chains, and for fragility mitigation purposes the optimal approach will be to use thousands of currencies (to reduce the complexity on the user side, we can use stable-coins to essentially create a common cross-chain currency standard, and any slight swings in the stable-coins on the user side would be interpreted in the UI as interest or demurrage so the user only needs to keep track of one unit of account).
We already discussed (1) and (2) in previous blog posts, and so today we will provide an introduction to some of the principles involved in (3).
Multichain
The model here is in many ways similar to the Bitshares model, except that we do not assume that DPOS (or any other POS) will be secure for arbitrarily small chains. Rather, seeing the general strong parallels between cryptoeconomics and institutions in wider society, particularly legal systems, we note that there exists a large body of shareholder law protecting minority stakeholders in real-world companies against the equivalent of a 51% attack (namely, 51% of shareholders voting to pay 100% of funds to themselves), and so we try to replicate the same system here by having every chain, to some degree, “police” every other chain either directly or indirectly through an interlinking transitive graph. The kind of policing required is simple – policing aganist double-spends and censorship attacks from local majority coalitions, and so the relevant guard mechanisms can be implemented entirely in code.
However, before we get to the hard problem of inter-chain security, let us first discuss what actually turns out to be a much easier problem: inter-chain interaction. What do we mean by multiple chains “interacting”? Formally, the phrase can mean one of two things:
- Internal entities (ie. scripts, contracts) in chain A are able to securely learn facts about the state of chain B (information transfer)
- It is possible to create a pair of transactions, T in A and T’ in B, such that either both T and T’ get confirmed or neither do (atomic transactions)
A sufficiently general implementation of (1) implies (2), since “T’ was (or was not) confirmed in B” is a fact about the state of chain B. The simplest way to do this is via Merkle trees, described in more detail here and here; essentially Merkle trees allow the entire state of a blockchain to be hashed into the block header in such a way that one can come up with a “proof” that a particular value is at a particular position in the tree that is only logarithmic in size in the entire state (ie. at most a few kilobytes long). The general idea is that contracts in one chain validate these Merkle tree proofs of contracts in the other chain.
A challenge that is greater for some consensus algorithms than others is, how does the contract in a chain validate the actual blocks in another chain? Essentially, what you end up having is a contract acting as a fully-fledged “light client” for the other chain, processing blocks in that chain and probabilistically verifying transactions (and keeping track of challenges) to ensure security. For this mechanism to be viable, at least some quantity of proof of work must exist on each block, so that it is not possible to cheaply produce many blocks for which it is hard to determine that they are invalid; as a general rule, the work required by the blockmaker to produce a block should exceed the cost to the entire network combined of rejecting it.
Additionally, we should note that contracts are stupid; they are not capable of looking at reputation, social consensus or any other such “fuzzy” metrics of whether or not a given blockchain is valid; hence, purely “subjective” Ripple-style consensus will be difficult to make work in a multi-chain setting. Bitcoin’s proof of work is (fully in theory, mostly in practice) “objective”: there is a precise definition of what the current state is (namely, the state reached by processing the chain with the longest proof of work), and any node in the world, seeing the collection of all available blocks, will come to the same conclusion on which chain (and therefore which state) is correct. Proof-of-stake systems, contrary to what many cryptocurrency developers think, can be secure, but need to be “weakly subjective” – that is, nodes that were online at least once every N days since the chain’s inception will necessarily converge on the same conclusion, but long-dormant nodes and new nodes need a hash as an initial pointer. This is needed to prevent certain classes of unavoidable long-range attacks. Weakly subjective consensus works fine with contracts-as-automated-light-clients, since contracts are always “online”.
Note that it is possible to support atomic transactions without information transfer; TierNolan’s secret revelation protocol can be used to do this even between relatively dumb chains like BTC and DOGE. Hence, in general interaction is not too difficult.
Security
The larger problem, however, is security. Blockchains are vulnerable to 51% attacks, and smaller blockchains are vulnerable to smaller 51% attacks. Ideally, if we want security, we would like for multiple chains to be able to piggyback on each other’s security, so that no chain can be attacked unless every chain is attacked at the same time. Within this framework, there are two major paradigm choices that we can make: centralized or decentralized.
| Centralized | Decentralized |
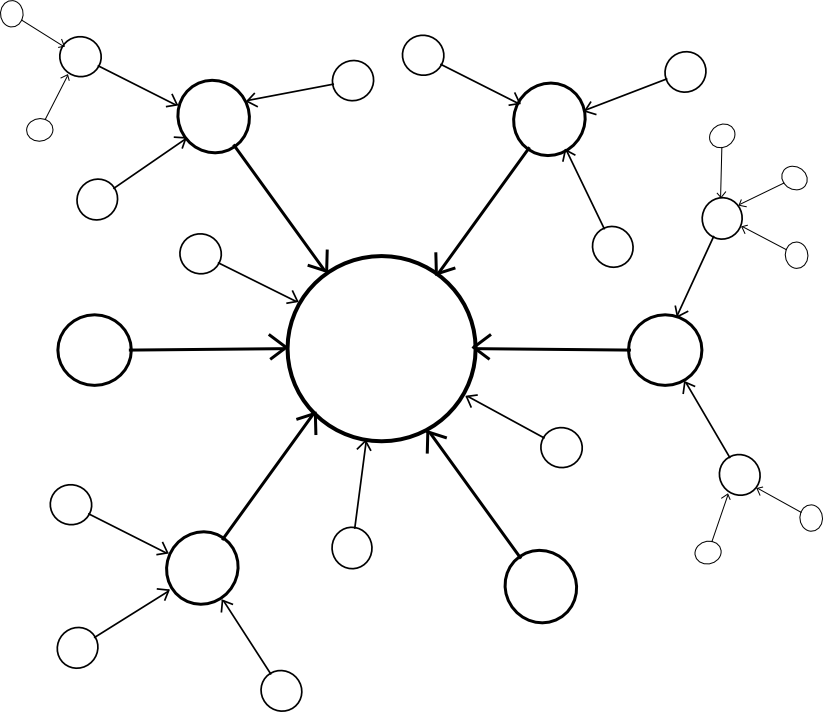 |
 |
A centralized paradigm is essentially every chain, whether directly or indirectly, piggybacking off of a single master chain; Bitcoin proponents often love to see the central chain being Bitcoin, though unfortunately it may be something else since Bitcoin was not exactly designed with the required level of general-purpose functionality in mind. A decentralized paradigm is one that looks vaguely like Ripple’s network of unique node lists, except working across chains: every chain has a list of other consensus mechanisms that it trusts, and those mechanisms together determine block validity.
The centralized paradigm has the benefit that it’s simpler; the decentralized paradigm has the benefit that it allows for a cryptoeconomy to more easily swap out different pieces for each other, so it does not end up resting on decades of outdated protocols. However, the question is, how do we actually “piggyback” on one or more other chains’ security?
To provide an answer to this question, we’ll first come up with a formalism called an assisted scoring function. In general, the way blockchains work is they have some scoring function for blocks, and the top-scoring block becomes the block defining the current state. Assisted scoring functions work by scoring blocks based on not just the blocks themselves, but also checkpoints in some other chain (or multiple chains). The general principle is that we use the checkpoints to determine that a given fork, even though it may appear to be dominant from the point of view of the local chain, can be determined to have come later through the checkpointing process.
A simple approach is that a node penalizes forks where the blocks are too far apart from each other in time, where the time of a block is determined by the median of the earliest known checkpoint of that block in the other chains; this would detect and penalize forks that happen after the fact. However, there are two problems with this approach:
- An attacker can submit the hashes of the blocks into the checkpoint chains on time, and then only reveal the blocks later
- An attacker may simply let two forks of a blockchain grow roughly evenly simultaneously, and then eventually push on his preferred fork with full force
To deal with (2), we can say that only the valid block of a given block number with the earliest average checkpointing time can be part of the main chain, thus essentially completely preventing double-spends or even censorship forks; every new block would have to point to the last known previous block. However, this does nothing against (1). To solve (1), the best general solutions involve some concept of “voting on data availability”; essentially, the participants in the checkpointing contract on each of the other chains would Schelling-vote on whether or not the entire data of the block was available at the time the checkpoint was made, and a checkpoint would be rejected if the vote leans toward “no”.
Note that there are two versions of this strategy. The first is a strategy where participants vote on data availability only (ie. that every part of the block is out there online). This allows the voters to be rather stupid, and be able to vote on availability for any blockchain; the process for determining data availability simply consists of repeatedly doing a reverse hash lookup query on the network until all the “leaf nodes” are found and making sure that nothing is missing. A clever way to force nodes to not be lazy when doing this check is to ask them to recompute and vote on the root hash of the block using a different hash function. Once all the data is available, if the block is invalid an efficient Merkle-tree proof of invalidity can be submitted to the contract (or simply published and left for nodes to download when determining whether or not to count the given checkpoint).
The second strategy is less modular: have the Schelling-vote participants vote on block validity. This would make the process somewhat simpler, but at the cost of making it more chain-specific: you would need to have the source code for a given blockchain in order to be able to vote on it. Thus, you would get fewer voters providing security for your chain automatically. Regardless of which of these two strategies is used, the chain could subsidize the Schelling-vote contract on the other chain(s) via a cross-chain exchange.
The Scalability Part
Up until now, we still don’t have any actual “scalability”; a chain is only as secure as the number of nodes that are willing to download (although not process) every block. Of course, there are solutions to this problem: challenge-response protocols and randomly selected juries, both described in the previous blog post on hypercubes, are the two that are currently best-known. However, the solution here is somewhat different: instead of setting in stone and institutionalizing one particular algorithm, we are simply going to let the market decide.
The “market” is defined as follows:
- Chains want to be secure, and want to save on resources. Chains need to select one or more Schelling-vote contracts (or other mechanisms potentially) to serve as sources of security (demand)
- Schelling-vote contracts serve as sources of security (supply). Schelling-vote contracts differ on how much they need to be subsidized in order to secure a given level of participation (price) and how difficult it is for an attacker to bribe or take over the schelling-vote to force it to deliver an incorrect result (quality).
Hence, the cryptoeconomy will naturally gravitate toward schelling-vote contracts that provide better security at a lower price, and the users of those contracts will benefit from being afforded more voting opportunities. However, simply saying that an incentive exists is not enough; a rather large incentive exists to cure aging and we’re still pretty far from that. We also need to show that scalability is actually possible.
The better of the two algorithms described in the post on hypercubes, jury selection, is simple. For every block, a random 200 nodes are selected to vote on it. The set of 200 is almost as secure as the entire set of voters, since the specific 200 are not picked ahead of time and an attacker would need to control over 40% of the participants in order to have any significant chance of getting 50% of any set of 200. If we are separating voting on data availability from voting on validity, then these 200 can be chosen from the set of all participants in a single abstract Schelling-voting contract on the chain, since it’s possible to vote on the data availability of a block without actually understanding anything about the blockchain’s rules. Thus, instead of every node in the network validating the block, only 200 validate the data, and then only a few nodes need to look for actual errors, since if even one node finds an error it will be able to construct a proof and warn everyone else.
Conclusion
So, what is the end result of all this? Essentially, we have thousands of chains, some with one application, but also with general-purpose chains like Ethereum because some applications benefit from the extremely tight interoperability that being inside a single virtual machine offers. Each chain would outsource the key part of consensus to one or more voting mechanisms on other chains, and these mechanisms would be organized in different ways to make sure they’re as incorruptible as possible. Because security can be taken from all chains, a large portion of the stake in the entire cryptoeconomy would be used to protect every chain.
It may prove necessary to sacrifice security to some extent; if an attacker has 26% of the stake then the attacker can do a 51% takeover of 51% of the subcontracted voting mechanisms or Schelling-pools out there; however, 26% of stake is still a large security margin to have in a hypothetical multi-trillion-dollar cryptoeconomy, and so the tradeoff may be worth it.
The true benefit of this kind of scheme is just how little needs to be standardized. Each chain, upon creation, can choose some number of Schelling-voting pools to trust and subsidize for security, and via a customized contract it can adjust to any interface. Merkle trees will need to be compatible with all of the different voting pools, but the only thing that needs to be standardized there is the hash algorithm. Different chains can use different currencies, using stable-coins to provide a reasonably consistent cross-chain unit of value (and, of course, these stable-coins can themselves interact with other chains that implement various kinds of endogenous and exogenous estimators). Ultimately, the vision of one of thousands of chains, with the different chains “buying services” from each other. Services might include data availability checking, timestamping, general information provision (eg. price feeds, estimators), private data storage (potentially even consensus on private data via secret sharing), and much more. The ultimate distributed crypto-economy.
The post Scalability, Part 3: On Metacoin History and Multichain appeared first on ethereum blog.